Нещасний user info php. Суперглобальний масив $_SERVER
Можливості ефективної організації, пошуку та поширення інформації давно становили інтерес для фахівців у галузі комп'ютерних технологій. Оскільки інформація в основному є текстом, що складається з алфавітно-цифрових символів, розробка засобів пошуку та обробки інформації за шаблонами, що описують текст, стала предметом серйозних теоретичних досліджень.
Пошук за шаблоном дозволяє не лише знаходити певні фрагменти тексту, а й замінювати їх на інші фрагменти. Одним із стандартних прикладів пошуку за шаблоном є команди пошуку/заміни в текстових редакторах - наприклад, у MS Word, Emacs та у моєму улюбленому редакторі vi. Всім користувачам UNIX добре відомі такі програми, як sed, awk та grep; багатство можливостей цих програм значною мірою обумовлено засобами пошуку за шаблоном. Механізми пошуку за шаблоном вирішують чотири основні завдання:
- пошук рядків, що точно збігаються із заданим шаблоном;
- пошук фрагментів рядків, що збігаються із заданим шаблоном;
- заміну рядків та підрядків за шаблоном;
- пошук рядків, із якими заданий шаблон не збігається.
Поява Web породила необхідність у більш швидких та ефективних засобах пошуку даних, які дозволяли б користувачам з усього світу знаходити потрібну інформацію серед мільярдів web-сторінок. Пошукові системи, онлайнові фінансові служби та сайти електронної комерції – все це стало б абсолютно марним без засобів аналізу гігантських обсягів даних у цих секторах. Справді, засоби обробки рядкової інформації є життєво важливою складовою практично будь-якого сектора, так чи інакше пов'язаного із сучасними інформаційними технологіями. У цьому розділі основна увага присвячена засобам обробки рядків у PHP. Ми розглянемо деякі стандартні рядкові функції (в мові їх більше 60!), а з наведених визначень та прикладів ви отримаєте відомості, необхідні для створення веб-додатків. Але перш ніж переходити до специфіки PHP, я хочу познайомити вас із базовим механізмом, завдяки якому стає можливим пошук за шаблоном. Йдеться про регулярні висловлювання.
Регулярні вирази
Регулярні вирази є основою всіх сучасних технологій пошуку за шаблоном. Регулярний вираз є послідовністю простих і службових символів, що описують шуканий текст. Іноді регулярні вирази бувають простими і зрозумілими (наприклад, слово dog), але часто в них присутні службові символи, що мають особливий сенс у синтаксисі регулярних виразів, наприклад,<(?)>.*<\/.?>.
У PHP існують два сімейства функцій, кожна з яких відноситься до певного типу регулярних виразів: у стилі POSIX або у стилі Perl. Кожен тип регулярних виразів має власний синтаксис і розглядається у відповідній частині розділу. На цю тему були написані численні підручники, які можна знайти як в Інтернеті, так і в книгарнях. Тому я наведу лише основні відомості про кожен тип, а подальшу інформацію за бажання ви зможете знайти самостійно. Якщо ви ще не знайомі з принципами роботи регулярних виразів, обов'язково прочитайте короткий вступний курс, що займає всю частину цього розділу. А якщо ви добре знаєтеся на цій галузі, сміливо переходьте до наступного розділу.
Синтаксис регулярних виразів (POSIX)
Структура регулярних виразів POSIX чимось нагадує структуру типових математичних виразів - різні елементи (оператори) поєднуються один з одним і утворюють складніші вирази. Однак саме сенс об'єднання елементів робить регулярні вирази таким потужним та виразним засобом. Можливості не обмежуються пошуком літерального тексту (наприклад, конкретного слова чи числа); ви можете провести пошук рядків з різною семантикою, але схожим синтаксисом - наприклад, всіх тегів HTML у файлі.
Найпростіший регулярний вираз збігається з одним літеральним символом - наприклад, вираз g збігається в таких рядках, як g , haggle та bag. Вираз, отриманий при поєднанні кількох літеральних символів, збігається за тими самими правилами - наприклад, послідовність gan збігається у будь-якому рядку, що містить ці символи (наприклад, gang, organize або Reagan).
Оператор | (вертикальна характеристика) перевіряє збіг однієї з кількох альтернатив. Наприклад, регулярний вираз php | zend перевіряє рядок на наявність php чи zend.
Квадратні дужки
Квадратні дужки () мають особливий сенс у контексті регулярних виразів - вони означають "будь-який символ з перерахованих у дужках". На відміну від регулярного виразу php, яке збігається у всіх рядках, що містять літеральний текст php, вираз збігається у будь-якому рядку, що містить символи р або h. Квадратні дужки відіграють важливу роль при роботі з регулярними виразами, оскільки в процесі пошуку часто виникає завдання пошуку символів із заданого інтервалу. Нижче наведено деякі часто використовувані інтервали:
- - збігається з будь-якою десятковою цифрою від 0 до 9;
- - збігається з будь-яким символом нижнього регістру від а до z;
- - збігається з будь-яким символом верхнього регістру від А до Z;
- -- збігається з будь-яким символом нижнього або верхнього регістру від до Z.
Звичайно, перераховані вище інтервали лише демонструють загальний принцип. Наприклад, можна скористатися інтервалом для позначення будь-якої десяткової цифри від 0 до 3 або інтервалом для позначення будь-якого символу нижнього регістра від b до v. Коротше кажучи, інтервали визначаються довільно.
Квантифікатори
Існує особливий клас службових символів, що означає кількість повторень окремого символу або конструкції, укладеної в квадратні дужки. Ці службові символи (+, * та (...)) називаються квантифікаторами.Принцип їх дії найпростіше пояснити на прикладах:
- р+ означає один або кілька символів р, що стоять поспіль;
- р * означає нуль і більше символів р, що стоять поспіль;
- р? означає нуль чи один символ р;
- р(2) означає два символи р, що стоять поспіль;
- р(2,3) означає від двох до трьох символів р, що стоять поспіль;
- р(2) означає два і більше символів р, що стоять поспіль.
Інші службові символи
Службові символи $ і ^ збігаються не з символами, а з певними позиціями у рядку. Наприклад, вираз р$ означає рядок, який завершується символом р, а вираз ^р - рядок, що починається з символу р.
- Конструкція [^a-zA-Z] збігається з будь-яким символом, не входитьу зазначені інтервали (a-z та A-Z).
- Службовий символ. (Точка) означає «будь-який символ». Наприклад, вираз р.р збігається із символом р, за яким слідує довільний символ, після чого знову слідує символ р.р.
Об'єднання службових символів призводить до появи складніших виразів. Розглянемо кілька прикладів:
- ^.(2)$ -- будь-який рядок, що містить рівнодва символи;
- (.*)-- довільна послідовність символів, укладена між<Ь>і(ймовірно, тегами HTML для виведення жирного тексту);
- p(hp)* - символ р, за яким слідує нуль і більше екземплярів послідовності hp (наприклад, phphphp).
Іноді потрібно знайти службові символи в рядках замість того, щоб використовувати їх в описаному спеціальному контексті. Для цього службові символи екрануються зворотною косою межею (\). Наприклад, для пошуку грошової суми в доларах можна скористатися виразом \$+, тобто «знак долара, за яким слідує одна або кілька десяткових цифр». Зверніть увагу на зворотну косу межу перед $. Можливими збігами для цього регулярного виразу є $42, $560 та $3.
Стандартні інтервальні вирази (символьні класи)
Для зручності програмування у стандарті POSIX було визначено деякі стандартні інтервальні вирази, також звані символьними класами(character classes). Символьний клас визначає один символ із заданого інтервалу - наприклад, букву алфавіту або цифру:
- [[: alpha:]] - алфавітний символ (aA-zZ);
- [[:digit:]]-цифра (0-9);
- [[: alnum:]] - алфавітний символ (aA-zZ) або цифра (0-9);
- [[:space:]] - перепустки (символи нового рядка, табуляції і т. д.).
Функції PHP для регулярних виразів (POSIX-сумісні)
В даний час PHP підтримує сім функцій пошуку з використанням регулярних виразів у стилі POSIX:
- еrеg();
- еrеg_rерlасе();
- eregi();
- eregi_replace();
- split();
- spliti();
- sql_regcase().
Опис цих функцій наведено в наступних розділах.
Функція еrеg() шукає у заданому рядку збіг шаблону. Якщо збіг знайдено, повертається TRUE, інакше повертається FALSE. Синтаксис функції ereg():
int ereg (string шаблон, string рядок [, array збіги])
Пошук здійснюється з урахуванням регістру алфавітних символів. Приклад використання ereg() для пошуку в рядках доменів.
$is_com - ereg("(\.)(com$)", $email):
// Функція повертає TRUE, якщо $email завершується символами ".com"
// Зокрема, пошук буде успішним для рядків
// "www.wjgilmore.com" та " [email protected]"
Зверніть увагу: через присутність службового символу $ регулярний вираз збігається лише у тому випадку, якщо рядок завершується символами.com. Наприклад, воно збігається у рядку "www.apress.com", але не співпадеу рядку "www.apress.com/catalog".
Необов'язковий параметр збігу містить масив збігів для всіх подвиражений, укладених у регулярному вираженні круглі дужки. У лістингу 8.1 показано, як з допомогою цього масиву розділити URL на кілька сегментів.
Лістинг 8.1. Виведення елементів масиву $regs
$url = "http://www.apress.com";
// Розділити $url на три компоненти: "http://www". "apress" та "com"
$www_url = ereg("^(http://www)\.([[:alnum:]+\.([[:alnum:]]+)". $url, $regs);
if ($www_url) // Якщо змінна $www_url містить URL
echo $regs; // Весь рядок "http://www.apress.com"
print "
";
echo $regs[l]; // "http://www"
print "
";
echo $regs; // "apress"
print "
";
echo $regs; // "com" endif;
При виконанні сценарію у лістингу 8.1 буде отримано наступний результат:
http://www.apress.com http://www apress com
Функція ereg_replace() шукає в заданому рядку збіг шаблону і замінює його новим фрагментом. Синтаксис функції ereg_replace():
string ereg_replace (string шаблон, string заміна, string рядку)
Функція ereg_replace() працює за тим самим принципом, що й ereg(), але її можливості розширені від простого пошуку до пошуку із заміною. Після заміни функція повертає модифікований рядок. Якщо збіги
відсутні, рядок залишається в колишньому стані. Функція ereg_replace(), як і еrеg(), враховує регістр символів. Нижче наведено простий приклад, що демонструє застосування цієї функції:
$copy_date = "Copyright 1999":
$copy_date = ereg_replace("(+)". "2000", $copy_date);
print $copy_date: // Виводиться рядок "Copyright 2000"
Засоби пошуку із заміною в мові PHP мають одну цікаву можливість - можливість використання зворотних посилань на частини основного виразу, укладені в круглі дужки. Зворотні посилання схожі на елементи необов'язкового параметра-масиву збігу функції еrеg() за одним винятком: зворотні посилання записуються у вигляді \0, \1, \2 і т. д., де \0 відповідає всьому рядку, \1 - успішному збігу першого виразу і т. д. Вираз може містити до 9 зворотних посилань. У наступному прикладі всі посилання URL у тексті замінюються працюючими гіперпосиланнями:
$url = "Apress (http://www.apress.com");
$url = ereg_replace("http://(()*)", " \\0", $ url);
// Виводиться рядок:
// Apress (http://www.apress.com)
Функція eregi() шукає у заданому рядку збіг шаблону. Синтаксис функції eregi():
int eregi (string шаблон, string рядок [, array збіги])
Пошук проводиться без облікурегістр алфавіту символи. Функція eregi() особливо зручна під час перевірки правильності введених рядків (наприклад, паролів). Використання функції eregi() показано в наступному прикладі:
$password = "abc";
if (! eregi("[[:alnum:]](8.10), $password) :
print "Неправильний password! Passwords must be from 8 through 10 characters in length.";
// Внаслідок виконання цього фрагмента виводиться повідомлення про помилку.
// оскільки довжина рядка "abc" не входить до дозволеного інтервалу
// Від 8 до 10 символів.
Функція eregi_replасе() працює так само, як ereg_replace(), за одним винятком: пошук здійснюється без урахування регістру символів. Синтаксис функції ereg_replace():
string eregi_replace (string шаблон, string заміна, string рядок)
Функція split() розбиває рядок на елементи, межі яких визначаються за заданим шаблоном. Синтаксис функції split():
array split (string шаблон, string рядок [, int поріг])
Необов'язковий параметр поріг визначає максимальну кількість елементів, на які ділиться рядок зліва направо. Якщо шаблон містить алфавітні символи, функція spl it() працює з урахуванням регістру символів. Наступний приклад демонструє використання функції split() для розбиття канонічної IP-адреси на триплети:
$ ip = "123.345.789.000"; // Канонічна IP-адреса
$iparr = split ("\.", $ip) // Оскільки точка є службовим символом.
// її необхідно екранувати.
print "$iparr
// Виводить "123"
print "$iparr
// Виводить "456"
print "$iparr
// Виводить "789"
print "$iparr
// Виводить "000"
Функція spliti() працює так само, як її прототип split(), за одним винятком: вона не враховуєрегістр символів. Синтаксис функції spliti():
array spliti (string шаблон, string рядок [, int поріг])
Зрозуміло, регістр символів важливий лише тому випадку, якщо шаблон містить алфавітні символи. Для інших символів виконання spliti() є повністю аналогічним split().
Допоміжна функція sql_regcase() містить кожен символ вхідного рядка в квадратні дужки і додає до нього парний символ. Синтаксис функції sql_regcase():
string sql_regcase (string рядок)
Якщо алфавітний символ існує у двох варіантах (верхній та нижній регістри), вираз у квадратних дужках міститиме обидва варіанти; інакше вихідний символ повторюється двічі. Функція sql_regcase() особливо зручна при використанні PHP з програмними пакетами, що підтримують регулярні вирази в одному регістрі. Приклад перетворення рядка функцією sql_regcase():
$version = "php 4.0";
print sql_regcase($version);
// Виводиться рядок [..]
Синтаксис регулярних виразів у стилі Perl
Перетворення рядка до верхнього та нижнього регістру
У PHP існує чотири функції, призначені для зміни регістру рядка:
- strtolower();
- strtoupper();
- ucfirst();
- ucwords().
Всі ці функції описані нижче.
strtolower()
Функція strtolower() перетворює всі алфавітні символи рядка до нижнього регістру. Синтаксис функції strtolower():
string strtolower(string рядок)
Неалфавітні символи не змінюються. Перетворення рядка до нижнього регістру функцією strtolower() продемонстровано в наступному прикладі:
$sentence = strtolower($sentence);
// "cooking and programming php є мої два favorite pastimes!"
Рядки можна перетворювати не лише до нижнього, а й до верхнього регістру. Перетворення виконується функцією strtoupper(), що має наступний синтаксис:
string strtoupper (string рядок)
Неалфавітні символи функцією не змінюються. Перетворення рядка до верхнього регістру функцією strtoupper() продемонстровано в наступному прикладі:
$sentence = "cooking and programming PHP є мої два favorite pastimes!";
$sentence = strtoupper($sentence);
// Після виклику функції $sentence містить рядок
// "COOKING AND PROGRAMMING PHP ARE MY TWO FAVORITE PASTIMES!"
Функція ucfirst() перетворює на верхній регістр перший символ рядка -- за умови, що він є алфавітним символом. Синтаксис функції ucfirst():
string ucfirst (string рядок)
Неалфавітні символи не змінюються. Перетворення першого символу рядка функцією ucfirst() продемонстровано в наступному прикладі:
&sentence = "cooking and programming PHP є мої два favorite pastimes!";
$sentence = ucfirst($sentence);
// Після виклику функції $sentence містить рядок
// "Cooking and programming PHP є мені два favorite pastimes!"
Функція ucwords() перетворює до верхнього регістру першу літеру кожного слова у рядку. Синтаксис функції ucwords():
string ucwords (string рядок")
Неалфавітні символи не змінюються. "Слово" визначається як послідовність символів, відокремлена від інших елементів рядка пробілами. У наступному прикладі продемонстровано перетворення перших символів слів функцією ucwords():
$sentence = "cooking and programming PHP є мої два favorite pastimes!";
$sentence = ucwords($sentence);
// Після виклику функції $sentence містить рядок
// "Cooking And Programming PHP Are My Two Favorite Pastimes!"
Проект: ідентифікація браузера
Кожен програміст, який намагається створити зручний веб-сайт, повинен враховувати відмінності у форматуванні сторінок під час перегляду сайту у різних браузерах та операційних системах. Хоча консорціум W3 (http://www.w3.org) продовжує публікувати стандарти, яких повинні дотримуватись програмісти при створенні web-додатків, розробники браузерів люблять доповнювати ці стандарти своїми маленькими «удосконаленнями», що зрештою викликає хаос та плутанину. Розробники часто вирішують цю проблему, створюючи різні сторінки для кожного типу браузера та операційної системи - при цьому обсяг роботи значно збільшується, зате підсумковий сайт ідеально підходить для будь-якого користувача. Результат – хороша репутація сайту та впевненість у тому, що користувач відвідає його знову.
Щоб користувач міг переглядати сторінку у форматі, що відповідає специфіці його браузера та операційної системи, з вхідного запиту на отримання сторінки витягується інформація про браузер та платформу. Після отримання необхідних даних, користувач перенаправляється на потрібну сторінку.
Нижче наведений проект (sniffer.php) показує, як використовувати функції PHP для роботи з регулярними виразами з метою отримання інформації за запитами. Програма визначає тип та версію браузера та операційної системи, після чого виводить отриману інформацію у вікні браузера. Але перш ніж переходити до безпосереднього аналізу програми, я хочу представити один із головних її компонентів - стандартну змінну PHP $HTTP_USER_AGENT. У цій змінній у рядковому форматі зберігаються різні відомості про браузер та операційну систему користувача - саме те, що нас цікавить. Цю інформацію можна легко вивести на екран лише однією командою:
echo $HTTP USER_AGENT;
При роботі в Internet Explorer 5.0 на комп'ютері з Windows 98 результат виглядатиме так:
Mozilla/4.0 (compatible; MSIE 5.0; Windows 98; DigExt)
Для Netscape Navigator 4.75 виводяться такі дані:
Mozilla/4.75 (Win98; U)
Sniffer.php витягує необхідні дані з $HTTP_USER_AGENT за допомогою функцій обробки рядків та регулярних виразів. Алгоритм програми на псевдокод:
- Визначити дві функції для ідентифікації браузера та операційної системи: browser_info() та opsys_info(). Почнемо з псевдокоду функції browser_info().
- Визначити тип браузера, використовуючи функцію егед(). Хоча ця функція працює повільніше за спрощені рядкові функції типу strstr(), в даному випадку вона зручніша, оскільки регулярне вираз дозволяє визначити версію браузера.
- Скористайтеся конструкцією if/elseif для ідентифікації наступних браузерів та їх версій: Internet Explorer, Opera, Netscape та браузер невідомого типу.
- Повернути інформацію про тип та версію браузера у вигляді масиву.
- Функція opsys_info() визначає тип операційної системи. На цей раз використовується функція strstr(), оскільки тип ОС визначається без застосування регулярних виразів.
- Скористайтеся конструкцією if/elseif для ідентифікації наступних систем: Windows, Linux, UNIX, Macintosh та невідома операційна система.
- Повернути інформацію про операційну систему.
Лістинг 8.3. Ідентифікація типу браузера та операційної системи клієнта
Файл: sniffer.php
Призначення: Ідентифікація типу/версії браузера та платформи
// Функція: browser_info
// Призначення: Повертає тип та версію браузера
function browser_info ($agent) (
// Визначити тип браузера
// Шукати сигнатуру Internet Explorer
if (ereg("MSIE (.(1,2))", $agent, $version))
$browse_type = "IE";
$browse version = $version;
// Шукати сигнатуру Opera
elseif (ereg("Opera (.(1,2))". $agent, $version)):
$browse_type = "Opera":
$browse_version = $version:
// Шукати сигнатуру Netscape. Перевірка браузера Netscape
// *повинна* виконуватися після перевірки Internet Explorer та Opera,
// оскільки всі ці браузери люблять повідомляти ім'я
// Mozilla разом із справжнім ім'ям.
elseif (ereg("Mozilla/(.(1,2))". $agent, $version)) :
$browse_type = "Netscape";
$browse_version = $version;
// Якщо це Internet Explorer, Opera чи Netscape.
// отже, ми виявили невідомий браузер,
$browse_type = "Unknown";
$browse_version = "Unknown";
// Повернути тип та версію браузера у вигляді масиву
return array ($browse_type, $browse_version);
) // Кінець функції browser_info
// Функція: opsys_info
// Призначення: Повертає інформацію про операційну систему користувача
function opsys_info($agent) (
// Ідентифікувати операційну систему
// Шукати сигнатуру Windows
if (strstr ($agent. "win")) :
$opsys = "windows";
// Шукати сигнатуру Linux
elseif (strstr($agent, "Linux")) :
$opsys = "Linux";
// Шукати сигнатуру UNIX
elseif (strstr (Sagent, "Unix")) :
$opsys = "Unix";
// Шукати сигнатуру Macintosh
elseif (strstr ($agent, "Mac")) :
$opsys = "Macintosh";
// Невідома платформа else:
$opsys = "Unknown";
// Повернути інформацію про операційну систему
list ($browse_type. $browse_version) = browser_info ($HTTP_USER_AGENT); Soperating_sys = opsysjnfo ($HTTP_USER_AGENT);
print "Browser Type: $browse_type
";
print "Browser Version: $browse_version
";
print "Operating System: $operating_sys
":
От і все! Наприклад, якщо користувач працює в браузері Netscape 4.75 на комп'ютері з Windows, буде виведено наступний результат:
Browser Type: Netscape
Browser Version: 4.75
Operating System: Windows
У наступному розділі ви навчитеся здійснювати переходи між сторінками і навіть створювати списки стилів (style sheets) для конкретних операційної системи та браузера.
Підсумки
У цьому розділі було викладено досить великий матеріал. Яка користь від мови програмування, якщо в ній не можна працювати з текстом? Ми розглянули такі теми:
- загальні відомості про регулярні вирази у стилях POSIX та Perl;
- стандартні функції PHP для роботи з регулярними виразами;
- зміна довжини рядка;
- визначення довжини рядка;
- альтернативні функції PHP для обробки рядкової інформації;
- перетворення простого тексту в HTML і навпаки;
- зміна регістру символів у рядках.
Наступний розділ відкриває другу частину книги - до речі, мою кохану. У ній ми почнемо знайомитися із засобами PHP, орієнтованими на Web, розглянемо процес динамічного створення вмісту, включення файлів та побудову загальних шаблонів. У подальших розділах частини 2 розглядаються робота з формами HTML, бази даних, відстеження даних сеансу та нетривіальні засоби роботи з шаблонами. Тримайтеся - починається найцікавіше!
Ті, хто більш-менш серйозно вивчав PHPзнають, що існує один дуже корисний глобальний масив у PHP, який називається $_SERVER. І ось хотілося б у цій статті розібрати найпопулярніші ключі та їх значення у цьому масиві, тому що їх знання просто обов'язкове навіть для початківця PHP-програміста.
Перш ніж приступити до глобальному масиву $_SERVER у PHP, одразу зроблю невелику підказку. Є чудова функція, вбудована у PHP, яка називається phpinfo(). Давайте відразу наведу приклад її використання:
phpinfo();
?>
В результаті виконання цього просто скрипту Ви побачите величезну таблицю з різними налаштуваннями інтерпретатора PHP, у тому числі, ближче до кінця буде таблиця значень глобального масиву $_SERVER. Там будуть перераховані всі ключі та всі відповідні їм значення. Чим це може допомогти Вам? А тим, що якщо Вам знадобиться те чи інше значення, і Ви забудете, як називається ключ, то за допомогою функції phpinfo()Ви можете завжди згадати його назву. Загалом, Ви виконаєте цей скрипт і одразу мене зрозумієте.
А тепер давайте перейдемо до найпопулярніших ключів масиву $_SERVER:
- HTTP_USER_AGENT- Цей ключ дозволяє дізнатися про характеристику клієнта. У більшості випадків це, безумовно, браузер, однак, не завжди. І знову ж таки, якщо браузер, то який, ось у цій змінній про це можна і дізнатися.
- HTTP_REFERER- Містить абсолютний шлях до того файлу ( PHP-скрипт, HTML-сторінка), з якого перейшли на цей скрипт. Грубо говорячи, звідки прийшов клієнт.
- SERVER_ADDR - IP-адресасервера.
- REMOTE_ADDR - IP-адресаклієнта.
- DOCUMENT_ROOT- фізичний шлях до кореневої директорії сайту. Ця опція задається через конфігураційний файл сервера Apache.
- SCRIPT_FILENAME- Фізичний шлях до викликаного скрипту.
- QUERY_STRING- Досить корисне значення, яке дозволяє отримати рядок із запитом, а далі можна займатися парсингом цього рядка.
- REQUEST_URI- ще корисніше значення, що містить як сам запит, а й разом із відносний шлях до скрипту від кореня. Це дуже часто використовується для видалення дублювання з index.php, тобто коли у нас такий URL: "http://mysite.ru/index.php"і" http://mysite.ru/ведуть на одну сторінку, а URLрізні, отже, дублювання, що погано позначиться на пошуковій оптимізації. І ось за допомогою REQUEST_URIми можемо визначити: з index.phpчи ні, був викликаний скрипт. І можемо зробити редирект з index.php(якщо він був у REQUEST_URI) на без index.php. В результаті, при наданні такого запиту: " http://mysite.ru/index.php?id=5", у нас відбуватиметься редирект на URL: "http://mysite.ru/?id=5". Тобто ми позбулися дублювання, вилучивши з URLцей index.php.
- SCRIPT_NAME- відносний шлях до скрипту, що викликається.
Мабуть, це все елементи глобального масиву $_SERVER в PHP, які використовуються регулярно. Їх треба знати та вміти використовувати, коли це необхідно.
У другому уроці ми напишемо ще два класи та повністю закінчимо внутрішню частину скрипту.
План
Мета серії уроків створити простий додаток, який дозволяє користувачам реєструватися, входити, виходити та змінювати налаштування. Клас, який міститиме всю інформацію про користувача буде називатися User і він буде визначений у файлі User.class.php. Клас, який відповідатиме за вхід\вихід буде називатися UserTools (UserTools.class.php).
Трохи про назву класів
Правильним тоном є називати файли з описом класу таким самим ім'ям, як і сам клас. Таким чином, легко визначити мету кожного файлу в папці з класами.
Також зазвичай наприкінці назви файлу класу додають .class або .inc. Таким чином, ми чітко визначаємо призначення файлу і можемо за допомогою. htaccess обмежити доступ до цих файлів.
Клас Користувачів (User.class.php)
Цей клас визначатиме кожного користувача. Зі зростанням цієї програми визначення "Користувач" може суттєво змінитись. На щастя, програмування ООП дозволяє легко додавати додаткові атрибути користувачів.
Конструктор
У цьому класі ми використовуватимемо конструктор - це функція, яка автоматично викликається при створенні чергової копії класу. Це дозволяє автоматично публікувати деякі атрибути після створення проекту. У цьому класі конструктор братиме єдиний аргумент: асоціативний масив, який містить один ряд з таблиці користувачів нашої БД.
require_once "DB.class.php"; class User ( public $id; public $username; public $hashedPassword; public $email;
public $joinDate;
//Конструктор викликається під час створення нового об'єкта//Таки an associative array with the DB ряд як an argument. function __construct($data) ( $this->id = (isset($data["id"])) ? $data["id"] : ""; $this->username = (isset($data[" username"])) ? $data["username"] : ""; $this->hashedPassword = (isset($data["password"])) ? $data["password"] : ""; >email = (isset($data["email"])) ? $data["email"] : ""; join_date"] : ""; )
public function save($isNewUser = false) ( //create a new database object. $db = new DB(); //if the user is already registered and we"re //just updating their info. if(!$isNewUser ) ( //set the data array $data = array("username" => ""$this->username"", "password" => ""$this->hashedPassword"",
"email" => ""$this->email"");
//update the row in the database $db->update($data, "users", "id = ".$this->id); )else ( //if the user is being registered for the first time. $data = array("username" => ""$this->username"", "password" => ""$this->hashedPassword"" , "email" => ""$this->email"", "join_date" => """.date("Y-m-d H:i:s",time())."""); id = $db->insert($data, users); $this->joinDate = time(); ) ) ?>
Пояснення
Перша частина коду, поза зоною класу, забезпечує підключення класу в БД (оскільки класі User є функція, що вимагає цей клас).
Замість змінних класу "protected" (використовувалися в 1-му уроці) ми визначаємо їх як "public". Це означає, що будь-який код поза класом має доступ до цих змінних під час роботи з об'єктом User.
Конструктор бере масив, у якому колонки у таблиці є ключами. Ми задаємо змінну класу, використовуючи $this->variablename. У прикладі даного класу ми передусім перевіряємо чи існує значення певного ключа. Якщо так, тоді ми прирівнюємо змінну класу до цього значення. В іншому випадку - порожній рядок. Код використовує коротку форму запису обороту if:
$ value = (3 == 4)? "A": "B";
У даному прикладі ми перевіряємо чи дорівнює 3 чотирьом! Якщо так - тоді $ value = "A", ні - $ value = "B". У прикладі результат $value = “B”.
Зберігаємо Інформацію про Користувачів у БД
Функція збереження використовується для внесення змін до таблиці баз даних з поточними значеннями в об'єкті User. Ця функція використовує клас БД, який ми створили у першому уроці. Використовуючи змінні класу, встановлюється масив $data. Якщо дані про користувача зберігаються вперше, $isNewUser передається як $true (за промовчанням false). Якщо $isNewUser = $true, тоді викликається функція insert() класу DB. Інакше викликається функція update(). В обох випадках інформація від об'єкта користувача буде збережена в БД.
Клас UserTools.class.php
Цей клас міститиме функції, які стосуються користувачів: login(), logout(), checkUsernameExists() та get(). Але з розширенням цієї програми, Ви можете додати ще багато інших.
//UserTools.class.php require_once "User.class.php"; require_once "DB.class.php";
class UserTools (
//Log the user in. Перші вибори до повідомлень, якщо //username і password match a row in the database. //If it is successful, set the session variables //and store the user object within.
public function login($username, $password)
{
$hashedPassword = md5($password); $result = mysql_query("SELECT * FROM users WHERE username = "$username" AND password = "$hashedPassword""); if(mysql_num_rows($result) == 1) ( $_SESSION["user"] = serialize(new User(mysql_fetch_assoc($result))); $_SESSION["login_time"] = time(); $_SESSION["logged_in "] = 1; return true; )else( return false; ) )
//Log the user out. Destroy the session variables. public function logout() ( unset($_SESSION["user"]); unset($_SESSION["login_time"]); unset($_SESSION["logged_in"]); session_destroy(); ) //Check to see if a username exists. //Ця є названа під час реєстрації в тому, що всі користувачі називаються unique. public function checkUsernameExists($username) ( $result = mysql_query("select id from users where username="$username""); if(mysql_num_rows($result) == 0) ( return false; )else( return true; )
}
//get a user //returns a User object. Такі users id as an input public function get($id) ( $db = new DB(); $result = $db->select("users", "id = $id"); return new User($result );
?>
Функція login()
Функція login() зрозуміла за назвою. Вона бере аргументи користувача $username і $password і перевіряє їхню відповідність. Якщо все збігається, створює об'єкт User з усією інформацією та зберігає його у сесії. Зверніть увагу, що ми використовуємо функцію PHP serialize(). Вона створює збережений варіант об'єкта, який можна скасувати за допомогою unserialize(). Також час логіну буде збережено. Це може використовуватися надалі для надання користувачам інформації про тривалість перебування на сайті.
Ви також можете помітити, що ми виставляємо $_SESSION["logged_in"] на 1. Це дозволяє нам легко перевірити на кожній сторінці чи залогінений користувач. Достатньо перевірити лише цю змінну.
Функція logout()
Також найпростіша функція. Функція PHP unset() очищає змінні пам'яті, тоді як session_destroy() видалить сесію.
Функція checkUsernameExists()
Хто знає англійську, легко зрозуміє функцію. Вона просто запитує БД, чи використаний подібний логін чи ні.
Функція get()
Ця функція бере унікальний ID користувача і робить запит до БД за допомогою класу DB, а саме функції select(). Вона візьме асоціативний масив із низкою інформації про користувача та створить новий об'єкт User, передаючи масив конструктору.
Де це можна використовувати? Наприклад, якщо Ви створите сторінку, яка повинна відображати специфічні профілі користувачів, Вам необхідно динамічно брати цю інформацію. Ось так Ви можете це зробити (припустимо УРЛ http://www.website.com/profile.php?userID=3)
//note: Ви маєте здійснити Open up Database connection first. //see Part 1 for further information on doing so. //You'll also have to make sure that you've included the class files.
$tools = New UserTools(); $user = $tools->get($_REQUEST["userID"]); echo "Username: ".$user->username.""; echo "Joined On: ".$user->joinDate."";
Легко! Правда?
Останній штрих серверної частини: global.inc.php
global.inc.php потрібний для кожної сторінки сайту. Чому? Таким чином, ми розмістимо всі звичайні операції, які нам знадобляться на сторінці. Наприклад, ми розпочнемо session_start(). З'єднання з БД також відкриється.
require_once "classes/UserTools.class.php";
require_once "classes/DB.class.php";
//connect to the database $db = новий DB(); $db->connect();
//initialize UserTools object $userTools = new UserTools(); //start the session
session_start();
//refresh session variables if logged in if(isset($_SESSION["logged_in"])) ( $user = unserialize($_SESSION["user"]); $_SESSION["user"] = serialize($userTools-> get($user->id));
Що він робить?
Тут трапляється кілька речей. Насамперед, ми відкриваємо з'єднання з базою.
Після з'єднання ми починаємо функцію session_start(). Функція створює сесію або продовжує поточну, якщо користувач вже зареєстрований. Оскільки наша програма розрахована на те, щоб користувачі входили, ця функція обов'язкова на кожній сторінці.
Далі ми перевіряємо чи закладений користувач. Якщо так - ми оновимо $_SESSION["user"], щоб відображати останню інформацію про користувача. Наприклад, якщо користувач змінює свій емейл, у сесії зберігатиметься ще старий. Але за допомогою авто оновлення такого не станеться.
На цьому друга частина добігла кінця! Завтра чекайте на заключний урок з цієї теми.
Всього найкращого!
Contents
$user_info
Це є всі ключі, які були визначені для $user_info в loadUserSettings(). Деякі є self-explanatory, для sure.
groups
array. Всі можливі членигрупи, що беруться до користувача. Keys do not matter. Values are the groups, sanitized as int, just in case. Це включає:
- Primary group
- Post count group
- Additional groups. Вони є завантажені в 데이터베이스 як comma-delimited string.
possibly_robot
bool. Це true if the agent matches a known spider if the feature is enabled, and if disabled, makes educated guess.
id
int Corresponds to the member"s database value "id_member".!}
username
name
string. Їх відтворений назва.
passwd
language
is_guest
is_admin
theme
last_login
int. Unix timestamp.
ip
$_SERVER["REMOTE_ADDR"]
ip2
$_SERVER["BAN_CHECK_IP"]
posts
int. Post count.
time_format
string. Custom format for strtftime().
time_offset
int. User's hourly offset від часу часу.
avatar
- url: string
- filename: string
- custom_dir: bool
- id_attach: int
smiley_set
messages
int. Номер PMs they have.
unread_messages
int. Число необхідних PMs є.
total_time_logged_in
buddies
String. The list of their buddies delimited by commas.
ignoreboards
String. List of boards вони мають ignored delimited by commas.
ignoreusers
String. List of users мають opted to ignore delimited by commas.
- In SMF 1.1.x тільки PMs get ignored.
- У SMF 2.0.x і назавжди, ця особливість має бути несприятливою для того, щоб вибрати повідомлення з неприйнятого користувача.
warning
int. Їх warning points.
permissions
query_see_board
List of all the boards they can see as part of prepared SQL statement.
query_wanna_see_board
List of boards they WANT to see as part of a prepared SQL statement.
mod_cache
is_mod
Boolean. Це false except in boards where the member is a moderator. It is always set.
лютий 5 , 2017
Я не знаю жодного php-фреймворку. Це сумно та соромно, але законом поки що не заборонено. А при цьому погратися із REST API хочеться. Проблема в тому, що php за промовчанням підтримує лише $_GET та $_POST. А для RESTful-сервісу треба вміти працювати ще й з PUT, DELETE та PATCH. І не дуже очевидно, як культурно обробити безліч запитів виду GET http://site.ru/users, DELETE http://site.ru/goods/5та іншого непотребства. Як завернути всі подібні запити в єдину точку, універсально розібрати їх на частини та запустити потрібний код обробки даних?
Майже будь-який php-фреймворк вміє робити це із коробки. Наприклад, Laravel, де роутинг реалізований зрозуміло та просто. Але якщо нам не потрібно прямо зараз займатися вивченням нової великої теми, а хочеться просто швидко завести проект з підтримкою REST API? Про це й йтиметься у статті.
Що має вміти наш RESTful-сервіс?
1. Підтримувати усі 5 основних типів запитів: GET, POST, PUT, PATCH, DELETE.
2. Розрулювати різноманітні маршрути виду
POST /goods
PUT /goods/(goodId)
GET /users/(userId)/info
та інші скільки завгодно довгі ланцюжки.
Увага: це стаття не про основи REST API
Я припускаю, що Ви вже знайомі з REST-підходом та розумієте, як це працює. Якщо ні, то в інтернетах багато чудових статей з основ REST – я не хочу дублювати їх, моя ідея – показати, як з REST працювати на практиці.
Який функціонал ми підтримуватимемо?
Розглянемо 2 сутності - товари та користувачі.
Для товарів наступні можливості:
- 1. GET /goods/(goodId)— Отримання інформації про товар
- 2. POST /goods- Додавання нового товару
- 3. PUT /goods/(goodId)- Редагування товару
- 4. PATCH /goods/(goodId)- Редагування деяких параметрів товару
- 5. DELETE /goods/(goodId)- Видалення товару
По користувачам для різноманітності розглянемо кілька варіантів із GET
- 1. GET /users/(userId)— Повна інформація про користувача
- 2. GET /users/(userId)/info— Тільки загальна інформація про користувача
- 3. GET /users/(userId)/orders- Список замовлень користувача
Як це почне працювати на нативному PHP?
Перше, що ми зробимо - це настроїмо.htaccess так, щоб усі запити перенаправлялися на файл index.php. Саме він і займатиметься вилученням даних.
Друге – визначимося, які дані нам потрібні та напишемо код для їх отримання – в index.php.
Нас цікавлять 3 типи даних:
- 1. Метод запиту (GET, POST, PUT, PATCH або DELETE)
- 2. Дані з URL-a, наприклад, users/(userId)/info - потрібні всі 3 параметри
- 3. Дані із тіла запиту
.htaccess
Створимо у корені проекту файл.htaccess
RewriteEngine On RewriteCond %(REQUEST_FILENAME) !-f RewriteRule ^(.+)$ index.php?q=$1
Цими загадковими рядками ми наказуємо робити так:
1 - надіслати всі запити будь-якого виду на цар-файл index.php
2 - зробити рядок в URL доступною в index.php в get-параметрі q. Тобто дані з URL виду /users/(userId)/infoми дістанемо із $_GET["q"].
index.php
Розглянемо рядок за рядком index.php. Спочатку отримаємо метод запиту.
// Визначаємо метод запиту $method = $_SERVER["REQUEST_METHOD"];
Потім дані з тіла запиту
// Отримуємо дані із тіла запиту $formData = getFormData($method);
Для GET та POST легко витягнути дані з відповідних масивів $_GET та $_POST. А ось для інших методів потрібно трохи перекрутитися. Код для них витягується з потоку php://input, код легко гуглиться, я лише написав загальну обгортку - функцію getFormData($method)
// Отримання даних з тіла запиту function getFormData($method) ( // GET або POST: дані повертаємо як if ($method === "GET") return $_GET; if ($method === "POST") return $_POST; // PUT, PATCH або DELETE $data = array(); = explode("=", $pair); if (count($item) == 2) ( $data = urldecode($item); ) ) return $data;
Тобто ми отримали необхідні дані, приховавши всі деталі в getFormData - ну і добре. Переходимо до найцікавішого – роутингу.
// Розбираємо url $url = (isset($_GET["q"])) ? $_GET["q"] : ""; $url = rtrim($url, "/"); $urls = explode("/", $url);
Вище ми дізналися, что.htaccess підкладе нам параметри з URL-a в q-параметр масиву $_GET. Тобто $_GET["q"] потрапить приблизно такий рядок: users/10. Незалежно від того, яким методом ми запит смикаємо.
А explode("/", $url)перетворює нам цей рядок на масив, з яким вже можна працювати. Таким чином, складайте скільки завгодно довгі ланцюжки запитів, наприклад,
GET /goods/page/2/limit/10/sort/price_asc
І будьте певні, отримайте масив
$urls = array("goods", "page", "2", "limit", "10", "sort", "price_asc");
Тепер у нас є всі дані, потрібно зробити з ними щось корисне. А зроблять це лише 4 рядки коду
// Визначаємо роутер та url data $router = $urls; $urlData = array_slice($urls, 1); // Підключаємо файл-роутер і запускаємо головну функцію include_once "routers/". $router. ".php"; route($method, $urlData, $formData);
Уловлюєте? Ми заводимо папку routers, в яку складаємо файли, що маніпулюють однією сутністю: товарами чи користувачами. При цьому домовляємося, що назва файлів збігаються з першим параметром urlData - він і буде роутером, $router. А з urlData цей роутер потрібно забрати, він нам більше не потрібен і використовується тільки для підключення потрібного файлу. array_slice($urls, 1)і витягне нам всі елементи масиву, крім першого.
Тепер залишилося підключити потрібний файл-роутер та запустити функцію route із трьома параметрами. Що це за function route? Умовимося, що у кожному файлі-роутері буде визначено таку функцію, яка за вхідними параметрами визначить, яку дію ініціював користувач, і виконає потрібний код. Зараз це стане зрозумілішим. Розглянемо перший запит – отримання даних про товар.
GET /goods/(goodId)
Файл routers/goods.php
// Роутер function route($method, $urlData, $formData) ( // Отримання інформації про товар // GET /goods/(goodId) if ($method === "GET" && count($urlData) === 1) ( // Отримуємо id товару $goodId = $urlData; // Витягуємо товар із бази... // Виводимо відповідь клієнту echo json_encode(array("method" => "GET", "id" => $goodId, "good" => "phone", "price" => 10000)); Return; ")); )
Вміст файлу - це велика функція route, яка залежно від переданих параметрів виконує потрібні дії. Якщо метод GET і urlData передано 1 параметр (goodId), це запит про отримання даних про товарі.
Увага: приклад дуже спрощений
У реалі, звичайно, потрібно додатково перевіряти вхідні параметри, наприклад, що goodId – це число. Замість того, щоб писати код тут, Ви, мабуть, підключіть потрібний клас. І для отримання товару створіть об'єкт цього класу та викличете у нього якийсь метод.
А може, передайте управління якомусь контролеру, який вже стурбується ініціалізацією необхідних моделей. Варіантів багато, ми розглядаємо лише загальну структуру коду.
У відповіді клієнту ми виводимо потрібні дані: назву товару та його ціну. id товару та метод у реальному додатку зовсім не обов'язкові. Покажемо їх тільки щоб переконатися, що викликається потрібний метод з правильними параметрами.
Давайте спробуємо на прикладі: відкрийте консоль браузера та виконайте код
$.ajax((url: "/examples/rest/goods/10", метод: "GET", dataType: "json", success: function(response)(console.log("response:", response)))) )
Код надішле запит на сервер, де я розгорнув подібну програму і виведе відповідь. Переконайтеся, що цікавить наш маршрут /goods/10справді відпрацював. На вкладці Network Ви помітите такий самий запит.
І так, /examples/rest - це кореневий шлях нашого тестового додатку на сайт
Якщо Вам звичніше користуватися curl-ом в консолі, то запустіть в терміналі це - відповідь буде та сама, та ще й із заголовками від сервера.
Curl -X GET https://сайт/examples/rest/goods/10 -i 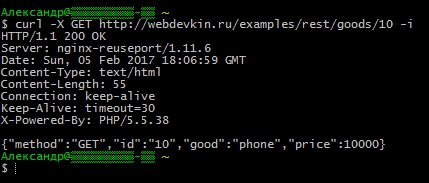
Наприкінці функції ми написали такий код.
// Повертаємо помилку header("HTTP/1.0 400 Bad Request"); echo json_encode(array("error" => "Bad Request"));
Він означає, що якщо ми помилилися з параметрами або маршрут, що запитується, не визначений, то повернемо клієнту 400-у помилку Bad Request. Додайте, наприклад, до URL щось на кшталт goods/10/another_paramі побачите помилку в консолі та відповідь 400 - кривий запит не пройшов.
За http-кодами відповідей сервера
Ми не будемо морочитися з виведенням різних кодів, хоча за REST це варто робити. Клієнтських помилок багато. Навіть у нашому простому випадку доречна 405 у разі неправильно переданого методу. Навмисно не хочу ускладнювати.
У разі успіху, сервер у нас завжди поверне 200 ОК. На хороше, при створенні ресурсу варто віддавати 201 Created. Але знов-таки у плані спрощення ці тонкощі ми відкинемо, а реальному проекті Ви їх легко реалізуєте самі.
Щиро кажучи, статтю закінчено. Думаю, Ви вже зрозуміли підхід, як розрулюються всі маршрути, виймаються дані, як це протестувати, як додавати нові запити і т.д. Але я для завершення образу наведу реалізацію 7 запитів, які ми позначили на початку статті. Принагідно наведу пару цікавих зауважень, а наприкінці викладу архів із вихідниками.
POST /goods
Додавання нового товару
// Додавання нового товару // POST /goods if ($method === "POST" && empty($urlData)) ( // Додаємо товар до бази... // Виводимо відповідь клієнту echo json_encode(array("method") => "POST", "id" => rand(1, 100), "formData" => $formData));
urlData зараз порожній, але використовується formData - ми її просто виведемо клієнту.
Як зробити "правильно"?
Згідно з канонами REST у post-запиті слід віддавати назад тільки id створеної сутності або url, за яким цю сутність можна отримати. Тобто у відповіді буде чи просто число - (goodId), або /goods/(goodId).
Чому я написав "правильно" у лапках? Тому, що REST - це набір не жорстких правил, а рекомендацій. І як реалізовуватимете саме Ви, залежить від Ваших переваг чи вже прийнятих угод на конкретному проекті.
Просто майте на увазі, що інший програміст, який читає код і обізнаний про REST-підхід, чекатиме у відповіді на post-запит id створеного об'єкта або url, за яким можна get-запитом витягнути дані про цей об'єкт.
Тестимо з консолі
$.ajax((url: "/examples/rest/goods/", метод: "POST", data: (good: "notebook", price: 20000), dataType: "json", success: function(response)( console.log("response:", response))))
Curl -X POST https://сайт/examples/rest/goods/ --data "good=notebook&price=20000" -i
PUT /goods/(goodId)
Редагування товару
// Оновлення всіх даних товару // PUT /goods/(goodId) if ($method === "PUT" && count($urlData) === 1) ( // Отримуємо id товару $goodId = $urlData; // Оновлюємо всі поля товару у базі... // Виводимо відповідь клієнту echo json_encode(array("method" => "PUT", "id" => $goodId, "formData" => $formData));
Тут уже всі дані використовуються по-повному. З urlData витягується ID товару, а з формиData - властивості.
Тестимо з консолі
$.ajax((url: "/examples/rest/goods/15", метод: "PUT", data: (good: "notebook", ціна: 20000), dataType: "json", success: function(response) (console.log("response:", response))))
Curl -X PUT https://сайт/examples/rest/goods/15 --data "good=notebook&price=20000" -i
PATCH /goods/(goodId)
Часткове оновлення товару
// Часткове оновлення даних товару // PATCH /goods/(goodId) if ($method === "PATCH" && count($urlData) === 1) ( // Отримуємо id товару $goodId = $urlData; // Оновлюємо лише зазначені поля товару в базі... // Виводимо відповідь клієнту echo json_encode(array("method" => "PATCH", "id" => $goodId, "formData" => $formData));
Тестимо з консолі
$.ajax((url: "/examples/rest/goods/15", метод: "PATCH", data: (price: 25000), dataType: "json", success: function(response)(console.log(" response:", response))))
Curl -X PATCH https://сайт/examples/rest/goods/15 --data "price=25000" -i
Навіщо ці понти з PUT і PATCH?
Хіба одного PUT мало? Хіба не виконують вони одну й ту саму дію – оновлюють дані об'єкта?
Саме так – зовні дія одна. Різниця в переданих даних.
PUT передбачає, що сервер передаються Усеполя об'єкта, а PATCH - тільки змінені. Ті, що передані в тілі запиту. Зверніть увагу, що у попередньому PUT ми передали і назву товару, і ціну. А в PATCH – лише ціну. Тобто, ми відправили на сервер лише змінені дані.
Чи потрібний Вам PATCH - вирішуйте самі. Але пам'ятайте про програміст, що читає код, про який я згадував вище.
DELETE /goods/(goodId)
Видалення товару
// Видалення товару // DELETE /goods/(goodId) if ($method === "DELETE" && count($urlData) === 1) ( // Отримуємо id товару $goodId = $urlData; // Видаляємо товар з бази... // Виводимо відповідь клієнту echo json_encode(array("method" => "DELETE", "id" => $goodId));
Тестимо з консолі
$.ajax((url: "/examples/rest/goods/20", метод: "DELETE", dataType: "json", success: function(response)(console.log("response:", response)))) )
Curl -X DELETE https://сайт/examples/rest/goods/20 -i
З DELETE-запитом все зрозуміло. Тепер давайте розглянемо роботу з користувачами - роутер users і відповідно файл users.php
GET /users/(userId)
Отримання всіх даних користувача. Якщо GET-запит виду /users/(userId), то ми повернемо всю інформацію про користувача, якщо додатково вказується /infoабо /ordersвідповідно, тільки загальну інформацію або список замовлень.
// Роутер function route($method, $urlData, $formData) ( // Отримання всієї інформації про користувача // GET /users/(userId) if ($method === "GET" && count($urlData) == = 1) ( // Отримуємо id товару $userId = $urlData; // Витягуємо всі дані про користувача з бази... // Виводимо відповідь клієнту echo json_encode(array("method" => "GET", "id" = > $userId, "info" => array("email" => " [email protected]", "name" => "Webdevkin"), "orders" => array(array("orderId" => 5, "summa" => 2000, "orderDate" => "12.01.2017"), array(" orderId" => 8, "summa" => 5000, "orderDate" => "03.02.2017")))); return; ) // Повертаємо помилку header("HTTP/1.0 400 Bad Request"); echo json_encode( array("error" => "Bad Request"));
Тестимо з консолі
$.ajax((url: "/examples/rest/users/5", метод: "GET", dataType: "json", success: function(response)(console.log("response:", response))) )
Curl-X GET https://сайт/examples/rest/users/5 -i
GET /users/(userId)/info
Загальна інформація про користувача
// Отримання загальної інформації про користувача // GET /users/(userId)/info if ($method === "GET" && count($urlData) === 2 && $urlData === "info") ( / / Отримуємо id товару $userId = $urlData; // Витягуємо загальні дані про користувача з бази... // Виводимо відповідь клієнту echo json_encode(array("method" => "GET", "id" => $userId, " info" => array("email" => " [email protected]", "name" => "Webdevkin"))); return;
Тестимо з консолі
$.ajax((url: "/examples/rest/users/5/info", метод: "GET", dataType: "json", success: function(response)(console.log("response:", response) )))
Curl-X GET https://сайт/examples/rest/users/5/info -i
GET /users/(userId)/orders
Отримання списку замовлень користувача
// Отримання замовлень користувача // GET /users/(userId)/orders if ($method === "GET" && count($urlData) === 2 && $urlData === "orders") ( // Отримуємо ID товару $userId = $urlData; // Витягуємо дані про замовлення користувача з бази... // Виводимо відповідь клієнту echo json_encode(array("method" => "GET", "id" => $userId, "orders" => array(array("orderId" => 5, "summa" => 2000, "orderDate" => "12.01.2017"), array("orderId" => 8, "summa" => 5000, "orderDate " => "03.02.2017")))); return; )
Тестимо з консолі
$.ajax((url: "/examples/rest/users/5/orders", метод: "GET", dataType: "json", success: function(response)(console.log("response:", response) )))
Curl -X GET https://сайт/examples/rest/users/5/orders -i
Підсумки та вихідники
Вихідники з прикладів статті
Як бачимо, організувати підтримку REST API на нативному php виявилося не так і складно і цілком законними способами. Головне - це підтримка маршрутів та нестандартних для php методів PUT, PATCH та DELETE.
Основний код, що реалізує цю підтримку, вмістився в 3 десятки рядків index.php. Решта – це вже обв'язка, яку можна реалізувати як завгодно. Я запропонував це зробити у вигляді файлів-роутерів, що підключаються, імена яких збігаються з сутностями Вашого проекту. Але можна підключити фантазію та знайти цікавіше рішення.





