Лоша потребителска информация php. Суперглобален масив $_SERVER
Възможностите за ефективно организиране, търсене и разпространение на информация отдавна представляват интерес за специалистите в областта на компютърните технологии. Тъй като информацията е предимно текст, състоящ се от буквено-цифрови знаци, разработването на средства за търсене и обработка на информация според шаблони, които описват текста, се превърна в обект на сериозни теоретични изследвания.
Търсенето по шаблон ви позволява не само да намирате конкретни фрагменти от текст, но и да ги заменяте с други фрагменти. Един стандартен пример за съпоставяне на шаблони са командите за намиране/замяна в текстови редактори – например MS Word, Emacs и любимия ми редактор, vi. Всички потребители на UNIX са запознати с програми като sed, awk и grep; Богатството на възможностите на тези програми до голяма степен се дължи на техните възможности за търсене на шаблони. Механизмите за търсене на шаблони решават четири основни проблема:
- търсене на низове, които точно отговарят на даден модел;
- търсене на фрагменти от низ, съответстващи на даден модел;
- замяна на низове и поднизове с помощта на шаблон;
- търсене на низове с даден модел не съответства.
Появата на мрежата създаде необходимост от по-бързи и по-ефективни инструменти за търсене на данни, които позволяват на потребителите по целия свят да намират необходимата им информация в милиарди уеб страници. Търсачките, онлайн финансовите услуги и сайтовете за електронна търговия биха били напълно безполезни без средствата за анализиране на огромните обеми от данни в тези сектори. Наистина, средствата за обработка на низова информация са жизненоважен компонент на почти всеки сектор, който по един или друг начин е свързан със съвременните информационни технологии. Тази глава се фокусира върху средствата за обработка на низове в PHP. Ще разгледаме някои стандартни низови функции (има повече от 60 от тях в езика!), а предоставените дефиниции и примери ще ви дадат необходимата информация за създаване на уеб приложения. Но преди да навлезем в спецификата на PHP, искам да ви запозная с основния механизъм, който прави търсенето по шаблон възможно. Говорим за регулярни изрази.
Регулярни изрази
Регулярните изрази са в основата на всички съвременни технологии за съвпадение на шаблони. Регулярният израз е поредица от прости и служебни знаци, които описват търсения текст. Понякога регулярните изрази са прости и ясни (например думата куче), но често съдържат специални знаци, които имат специално значение в синтаксиса на регулярните изрази - например,<(?)>.*<\/.?>.
В PHP има две семейства функции, всяко от които е различен тип регулярен израз: в стил POSIX или в стил Perl. Всеки тип регулярен израз има свой собствен синтаксис и се обсъжда в съответната част на главата. По тази тема са написани множество учебници, които могат да бъдат намерени както в мрежата, така и в книжарниците. Затова ще предоставя само основна информация за всеки тип, а вие можете да намерите допълнителна информация сами, ако желаете. Ако все още не сте запознати с това как работят регулярните изрази, не забравяйте да прочетете краткия уводен урок, който заема останалата част от този раздел. И ако сте добре запознати с тази област, не се колебайте да преминете към следващия раздел.
Синтаксис на регулярен израз (POSIX)
Структурата на регулярните изрази на POSIX донякъде напомня структурата на типичните математически изрази - различни елементи (оператори) се комбинират един с друг, за да образуват по-сложни изрази. Усещането за комбиниране на елементи обаче прави регулярните изрази толкова мощен и изразителен инструмент. Възможностите не се ограничават до търсене на буквален текст (като конкретна дума или число); можете да търсите низове с различна семантика, но подобен синтаксис -- например всички HTML тагове във файл.
Най-простият регулярен израз съвпада с един литерален знак - например изразът g съвпада с низове като g , пазарене и чанта. Израз, получен в резултат на конкатенация на множество литерални символи, съвпада според едни и същи правила -- например последователността gan съвпада във всеки низ, съдържащ тези знаци (например gang, organize или Reagan).
Оператор | (вертикална лента) тества дали една от няколко алтернативи съвпада. Например регулярният израз php | zend проверява низа за php или zend.
Квадратни скоби
Квадратните скоби () имат специално значение в контекста на регулярните изрази - те означават "всеки знак, посочен в скобите." За разлика от регулярния израз на php, който съвпада на всички редове, съдържащи текст на php литерал, изразът съвпада на всеки ред, съдържащ знаците p или h. Квадратните скоби играят важна роля при работа с регулярни изрази, тъй като процесът на търсене често включва задачата за намиране на знаци от даден интервал. По-долу са някои често използвани интервали:
- -- съвпада с всяка десетична цифра от 0 до 9;
- -- съответства на всяка малка буква от a до z;
- -- съвпада с всеки главен знак от A до Z;
- -- съответства на всяка малка или главна буква от a до z.
Разбира се, интервалите, изброени по-горе, само демонстрират общия принцип. Например, можете да използвате интервал, за да представите всяка десетична цифра от 0 до 3, или интервал, за да представите всеки малък знак от b до v. Накратко, интервалите се определят напълно произволно.
Квантори
Има специален клас служебни знаци, които показват броя на повторенията на един знак или конструкция, оградена в квадратни скоби. Тези специални знаци (+, * и (...)) се извикват квантификатори.Принципът на тяхното действие е най-лесно да се обясни с примери:
- p+ означава един или повече p знака в ред;
- p* означава нула или повече p символа в ред;
- R? означава нула или един знак p;
- p(2) означава два p символа в един ред;
- p(2,3) означава два до три p знака подред;
- p(2,) означава два или повече p знака в ред.
Други служебни герои
Служебните знаци $ и ^ не съответстват на символи, а на конкретни позиции в низа. Например изразът p$ означава низ, който завършва със знака p, а изразът ^p означава низ, който започва със знака p.
- Конструкцията [^a-zA-Z] отговаря на произволен знак които не са включенина посочените интервали (a-z и A-Z).
- Сервизен символ. (точка) означава "всеки знак". Например изразът p.p съвпада със знака p, последван от произволен знак, последван отново от знака p.
Комбинирането на служебни символи води до по-сложни изрази. Нека да разгледаме няколко примера:
- ^.(2)$ -- всеки низ, съдържащ гладкадва знака;
- (.*)-- произволна последователност от знаци между<Ь>И(вероятно HTML тагове за показване на удебелен текст);
- p(hp)* -- символът p, последван от нула или повече екземпляри на последователността hp (например phphphp).
Понякога трябва да намерите специални символи в низове, вместо да ги използвате в описания специален контекст. За да направите това, служебните знаци се екранират с обратна наклонена черта (\). Например, за да търсите пари в долари, можете да използвате израза \$+, тоест „знак за долар, последван от една или повече десетични цифри“. Обърнете внимание на обратната наклонена черта преди $. Възможните съвпадения за този регулярен израз са $42, $560 и $3.
Стандартни интервални изрази (класове знаци)
За по-лесно програмиране стандартът POSIX дефинира някои стандартни интервални изрази, наричани още класове на знаци(класове на знаци). Клас знаци дефинира един знак от даден диапазон -- например буква от азбуката или число:
- [[:alpha:]] -- азбучен знак (aA-zZ);
- [[:цифра:]]-цифра (0-9);
- [[:alnum:]] -- буквен знак (aA-zZ) или число (0-9);
- [[:space:]] -- интервал (нов ред, табулатори и т.н.).
PHP функции за работа с регулярни изрази (POSIX-съвместими)
В момента PHP поддържа седем функции за търсене, използвайки регулярни изрази в стил POSIX:
- ereg();
- ereg_replace();
- eregi();
- eregi_replace();
- разделяне();
- разделяне();
- sql_regcase().
Описанията на тези функции са дадени в следващите раздели.
Функцията ereg() търси в даден низ съвпадение за шаблон. Ако се намери съвпадение, се връща TRUE, в противен случай се връща FALSE. Синтаксисът на функцията ereg() е:
int ereg (образец на низ, низ низ [, съвпадения на масив])
Търсенето се извършва, като се вземат предвид буквите. Пример за използване на ereg() за търсене в низове domains.com:
$is_com - ereg("(\.)(com$)", $имейл):
// Функцията връща TRUE, ако $email завършва със знаци ".com".
// По-специално, търсенето ще бъде успешно за низове
// "www.wjgilmore.com" и " [имейл защитен]"
Имайте предвид, че поради наличието на символа $, регулярният израз съвпада само ако низът завършва с .com знаци. Например, ще съответства на низа "www.apress.com", но няма да съвпаднев реда "www.apress.com/catalog".
Незадължителният параметър за съвпадение съдържа масив от съвпадения за всички подизрази, затворени в скоби в регулярния израз. Листинг 8.1 показва как да използвате този масив, за да разделите URL на множество сегменти.
Списък 8.1. Отпечатване на елементи от масива $regs
$url = "http://www.apress.com";
// Разделете $url на три компонента: "http://www". "apress" и "com"
$www_url = ereg("^(http://www)\.([[:alnum:]+\.([[:alnum:]]+)". $url, $regs);
if ($www_url) : // Ако $www_url съдържа URL
ехо $regs; // Целият низ "http://www.apress.com"
печат "
";
ехо $regs[l]; // "http://www"
печат "
";
ехо $regs; // "apress"
печат "
";
ехо $regs; // "com" endif;
Изпълнението на скрипта в Листинг 8.1 дава следния резултат:
http://www.apress.com http://www apress com
Функцията ereg_replace() търси в даден низ съвпадение за шаблон и го замества с нов фрагмент. Синтаксис на функцията ereg_replace():
низ ereg_replace (модел на низ, замяна на низ, низ на низ)
Функцията ereg_replace() работи на същия принцип като ereg(), но нейните възможности са разширени от обикновено търсене към търсене със замяна. След като извърши замяната, функцията връща модифицирания низ. Ако има съвпадения
липсват, линията остава в същото състояние. Функцията ereg_replace(), подобно на ereg(), е чувствителна към главни и малки букви. По-долу е даден прост пример, демонстриращ използването на тази функция:
$copy_date = "Авторско право 1999":
$copy_date = ereg_replace("(+)". "2000", $copy_date);
print $copy_date: // Отпечатва низа "Copyright 2000"
Една интересна характеристика на инструментите за търсене и замяна на PHP е възможността да се използват препратки към части от основния израз, затворени в скоби. Обратните препратки са подобни на елементите на незадължителния параметър за съвпадение на ereg(), с едно изключение: обратните препратки се записват като \0, \1, \2 и т.н., където \0 съвпада с целия низ, \1 съвпада с успешно съвпадение първи подизраз и т.н. Изразът може да съдържа до 9 обратни връзки. Следният пример заменя всички URL връзки в текста с работещи хипервръзки:
$url = "Apress (http://www.apress.com");
$url = ereg_replace("http://(()*)", " \\0", $url);
// Показва се редът:
// Apress (http://www.apress.com)
Функцията eregi() търси в даден низ съвпадение за модел. Синтаксис на функцията eregi():
int eregi (образец на низ, низ низ [, съвпадения на масив])
Издирването е в ход като изключимрегистър на буквите. Функцията eregi() е особено полезна за проверка на валидността на въведените низове (например пароли). Използването на функцията eregi() е демонстрирано в следния пример:
$парола = "abc";
if (! eregi("[[:alnum:]](8.10), $password) :
print "Невалидна парола! Паролите трябва да са с дължина от 8 до 10 знака.";
// В резултат на изпълнението на този фрагмент се показва съобщение за грешка.
// защото дължината на низа "abc" не е в рамките на разрешения интервал
// от 8 до 10 символа.
Функцията eregi_replace() работи точно по същия начин като ereg_replace(), с едно изключение: търсенето не е чувствително към главни и малки букви. Синтаксис на функцията ereg_replace():
низ eregi_replace (шаблон на низ, замяна на низ, низ на низ)
Функцията split() разделя низ на елементи, чиито граници се определят от даден модел. Синтаксисът на функцията split() е:
разделяне на масив (модел на низ, низ на низ [, int праг])
Незадължителният прагов параметър определя максималния брой елементи, на които низът е разделен отляво надясно. Ако шаблонът съдържа азбучни знаци, функцията spl it() е чувствителна към главни и малки букви. Следният пример демонстрира използването на функцията split() за разделяне на каноничен IP адрес на триплети:
$ip = "123.345.789.000"; // Каноничен IP адрес
$iparr = split ("\.", $ip) // Тъй като точката е служебен знак.
// трябва да се екранира.
отпечатайте "$iparr
"; // Извежда "123"
отпечатайте "$iparr
"; // Извежда "456"
отпечатайте "$iparr
"; // Извежда "789"
отпечатайте "$iparr
"; // Извежда "000"
Функцията spliti() работи точно като своя прототип split(), с едно изключение: тя не взема предвидрегистър на символите. Синтаксисът на функцията spliti() е:
разделяне на масив (образец на низ, низ низ [, int праг])
Разбира се, регистърът на буквите е важен само ако моделът съдържа буквени знаци. За други символи изпълнението на spliti() е точно същото като split().
Помощната функция sql_regcase() затваря всеки знак във входния низ в квадратни скоби и добавя съответстващия знак към него. Синтаксис на функцията sql_regcase():
низ sql_regcase (низ низ)
Ако даден азбучен знак съществува в два варианта (главен и малък), изразът в квадратни скоби ще съдържа и двата варианта; в противен случай оригиналният знак се повтаря два пъти. Функцията sql_regcase() е особено полезна, когато използвате PHP със софтуерни пакети, които поддържат регулярни изрази с единичен регистър. Пример за конвертиране на низ с помощта на функцията sql_regcase():
$version = "php 4.0";
печат sql_regcase ($ версия);
// Показва низа [..]
Синтаксис на регулярен израз в стил Perl
Преобразуване на низ в главни и малки букви
В PHP има четири функции, предназначени да променят регистъра на буквите на низ:
- strtolower();
- strtoupper();
- ucfirst();
- ucwords().
Всички тези функции са описани подробно по-долу.
strtolower()
Функцията strtolower() преобразува всички азбучни знаци в низ в малки букви. Синтаксисът на функцията strtolower() е:
низ strtolower(низ низ)
Неазбучните знаци не се променят от функцията. Преобразуването на низ в малки букви с помощта на strtolower() е демонстрирано в следния пример:
$изречение = strtolower($изречение);
// "готвенето и програмирането на php са двете ми любими забавления!"
Низовете могат да се преобразуват не само в малки, но и в главни букви. Преобразуването се извършва от функцията strtoupper(), която има следния синтаксис:
низ strtoupper (низ низ)
Неазбучните знаци не се променят от функцията. Преобразуването на низ в главни букви с помощта на strtoupper() е демонстрирано в следния пример:
$sentence = "готвенето и програмирането на PHP са двете ми любими забавления!";
$изречение = strtoupper($изречение);
// След извикване на функцията $изречение съдържа низа
// "ГОТВЕНЕТО И ПРОГРАМИРАНЕТО НА PHP СА ДВЕТЕ МИ ЛЮБИМИ ЗАБАВЛЕНИЯ!"
Функцията ucfirst() преобразува първия знак от низ в главна буква, при условие че е азбучен знак. Синтаксис на функцията ucfirst():
низ ucfirst (низ низ)
Неазбучните знаци не се променят от функцията. Преобразуването на първия символ на низ от функцията ucfirst() е демонстрирано в следния пример:
&sentence = "готвенето и програмирането на PHP са двете ми любими забавления!";
$изречение = ucfirst($изречение);
// След извикване на функцията $изречение съдържа низа
// "Готвенето и програмирането на PHP са двете ми любими забавления!"
Функцията ucwords() преобразува първата буква от всяка дума в низ в главна буква. Синтаксис на функцията ucwords():
низ ucwords (низ низ")
Неазбучните знаци не се променят от функцията. „Думата“ се дефинира като поредица от знаци, разделени от други елементи на низ с интервали. Следващият пример демонстрира как функцията ucwords() преобразува първите знаци на думите:
$sentence = "готвенето и програмирането на PHP са двете ми любими забавления!";
$изречение = ucwords($изречение);
// След извикване на функцията $изречение съдържа низа
// "Готвенето и програмирането на PHP са двете ми любими занимания!"
Проект: Идентификация на браузъра
Всеки програмист, който се опитва да създаде удобен за потребителя уебсайт, трябва да вземе предвид разликите във форматирането на страницата, когато разглежда сайта в различни браузъри и операционни системи. Въпреки че консорциумът W3 (http://www.w3.org) продължава да публикува стандарти, към които програмистите трябва да се придържат, когато създават уеб приложения, разработчиците на браузъри обичат да добавят свои собствени малки „подобрения“ към тези стандарти, което в крайна сметка причинява хаос и объркване . Разработчиците често решават този проблем, като създават различни страници за всеки тип браузър и операционна система - това значително увеличава натоварването, но полученият сайт е идеален за всеки потребител. Резултатът е добра репутация на сайта и увереност, че потребителят ще го посети отново.
За да позволи на потребителя да види страницата във формат, който е подходящ за неговия браузър и операционна система, информацията за браузъра и платформата се извлича от входящата заявка за страница. След получаване на необходимите данни, потребителят се пренасочва към желаната страница.
Проектът по-долу (sniffer.php) показва как да използвате PHP функции за работа с регулярни изрази за извличане на информация от заявки. Програмата определя типа и версията на браузъра и операционната система и след това показва получената информация в прозореца на браузъра. Но преди да премина към същинския анализ на програмата, искам да представя един от основните й компоненти - стандартната PHP променлива $HTTP_USER_AGENT. Тази променлива съхранява различна информация за браузъра и операционната система на потребителя в низов формат - точно това, което ни интересува. Тази информация може лесно да се покаже на екрана само с една команда:
echo $HTTP USER_AGENT;
Когато стартирате Internet Explorer 5.0 на компютър с Windows 98, резултатът ще изглежда така:
Mozilla/4.0 (съвместим; MSIE 5.0; Windows 98; DigExt)
За Netscape Navigator 4.75 се показват следните данни:
Mozilla/4.75 (Win98; U)
Sniffer.php извлича необходимите данни от $HTTP_USER_AGENT чрез обработка на низове и функции за регулярен израз. Програмен алгоритъм в псевдокод:
- Дефинирайте две функции за идентифициране на браузъра и операционната система: browser_info() и opsys_info(). Нека започнем с псевдокода на функцията browser_info().
- Определете типа браузър с помощта на функцията eged(). Въпреки че тази функция е по-бавна от опростените низови функции като strstr(), тя е по-удобна в този случай, тъй като регулярният израз ви позволява да определите версията на браузъра.
- Използвайте конструкцията if/elseif, за да идентифицирате следните браузъри и техните версии: Internet Explorer, Opera, Netscape и браузър от неизвестен тип.
- Връща информация за типа и версията на браузъра като масив.
- Функцията opsys_info() определя типа на операционната система. Този път се използва функцията strstr(), тъй като типът на ОС се определя без използване на регулярни изрази.
- Използвайте конструкцията if/elseif, за да идентифицирате следните системи: Windows, Linux, UNIX, Macintosh и неизвестна операционна система.
- Върнете информация за операционната система.
Листинг 8.3. Идентифициране на типа браузър и клиентската операционна система
Файл: sniffer.php
Цел: Идентификация на типа/версията на браузъра и платформата
// Функция: browser_info
// Цел: Връща тип и версия на браузъра
функция browser_info ($agent) (
// Определяне на типа на браузъра
// Търсене на подпис на Internet Explorer
if (ereg("MSIE (.(1,2))", $agent, $version))
$browse_type = "IE";
$преглед версия = $версия;
// Търсене на подпис на Opera
elseif (ereg("Opera (.(1,2))". $agent, $version)):
$browse_type = "Opera":
$browse_version = $версия:
// Търсене на подпис на Netscape. Проверка на браузъра Netscape
// *трябва* да се направи след проверка на Internet Explorer и Opera,
// защото всички тези браузъри обичат да докладват името
// Mozilla заедно с истинското име.
elseif (ereg("Mozilla/(.(1,2))". $agent, $version)) :
$browse_type = "Netscape";
$browse_version = $версия;
// Освен ако не е Internet Explorer, Opera или Netscape.
// означава, че сме открили непознат браузър,
$browse_type = "Неизвестно";
$browse_version = "Неизвестно";
// Връща тип и версия на браузъра като масив
върнат масив ($browse_type, $browse_version);
) // Край на функцията browser_info
// Функция: opsys_info
// Цел: Връща информация за операционната система на потребителя
функция opsys_info($agent) (
// Идентифицирайте операционната система
// Търсене на Windows подпис
if (strstr($agent. "win")):
$opsys = "прозорци";
// Търсене на подпис на Linux
elseif (strstr($agent, "Linux")):
$opsys = "Linux";
// Търсене на UNIX подпис
elseif (strstr (Sagent, "Unix")):
$opsys = "Unix";
// Потърсете подпис на Macintosh
elseif (strstr($agent, "Mac")):
$opsys = "Macintosh";
// Друга неизвестна платформа:
$opsys = "Неизвестно";
// Връща информация за операционната система
списък ($browse_type. $browse_version) = browser_info ($HTTP_USER_AGENT); Soperating_sys = opsysjnfo($HTTP_USER_AGENT);
print "Тип на браузъра: $browse_type
";
print "Версия на браузъра: $browse_version
";
print "Операционна система: $operating_sys
":
Това е всичко! Например, ако потребителят използва браузъра Netscape 4.75 на компютър с Windows, ще се покаже следният изход:
Тип браузър: Netscape
Версия на браузъра: 4.75
Операционна система: Windows
В следващата глава ще научите как да навигирате между страниците и дори да създавате таблици със стилове за конкретни операционни системи и браузъри.
Резултати
Тази глава обхващаше доста материал. Каква полза от език за програмиране, ако не можете да работите с текст на него? Обхванахме следните теми:
- обща информация за регулярните изрази в POSIX и Perl стилове;
- стандартни PHP функции за работа с регулярни изрази;
- промяна на дължината на линията;
- определяне на дължината на низ;
- алтернативни PHP функции за обработка на низова информация;
- конвертиране на обикновен текст в HTML и обратно;
- промяна на регистъра на буквите в низовете.
Следващата глава отваря втората част на книгата – между другото, любимата ми. В него ще започнем да изследваме уеб-ориентираните инструменти на PHP, ще разгледаме процеса на динамично създаване на съдържание, включително файлове, и изграждане на общи шаблони. По-късните глави в част 2 обхващат работата с HTML формуляри, бази данни, проследяване на данни от сесии и разширени инструменти за шаблони. Дръжте се - забавлението е на път да започне!
Тези, които са учили повече или по-малко сериозно PHPзнайте, че има един много полезен глобален масив в PHPкоето се нарича $_SERVER. И в тази статия бих искал да анализирам най-популярните ключове и техните стойности в този масив, тъй като познаването им е просто задължително дори за начинаещ PHP програмист.
Преди да започнеш глобален масив $_SERVER в PHP, веднага ще ви дам малък намек. Има вградена страхотна функция PHP, което се нарича phpinfo(). Нека веднага да дадем пример за използването му:
phpinfo();
?>
В резултат на изпълнението на този прост скрипт ще видите огромна таблица с различни Настройки на PHP интерпретатора, включително, близо до края ще има таблица със стойности глобален масив $_SERVER. Той ще изброи всички ключове и всички съответстващи им стойности. Как това може да ви помогне? И факт е, че ако имате нужда от тази или онази стойност и забравите как се нарича ключът, тогава използвайте функцията phpinfo()Винаги можете да запомните името му. Като цяло ще изпълните този скрипт и веднага ще ме разберете.
Сега да преминем към най-популярните към ключовете на масива $_SERVER:
- HTTP_USER_AGENT- този ключ ви позволява да разберете характеристиките на клиента. В повечето случаи това със сигурност е браузърът, но не винаги. И отново, ако това е браузър, тогава кой, можете да разберете за него в тази променлива.
- HTTP_REFERER- съдържа абсолютния път до този файл ( PHP скрипт, HTML страница), от който преминахме към този скрипт. Грубо казано откъде идва клиента.
- SERVER_ADDR - IP адрессървър.
- REMOTE_ADDR - IP адресклиент.
- DOCUMENT_ROOT- физически път до основната директория на сайта. Тази опция се настройва чрез Конфигурационен файл на сървъра Apache.
- SCRIPT_FILENAME- физически път до извикания скрипт.
- QUERY_STRING- много полезна стойност, която ви позволява да получите низ със заявка и след това можете да анализирате този низ.
- REQUEST_URI- още по-полезна стойност, която съдържа не само самата заявка, но и относителния път към извикания скрипт от корена. Това много често се използва за премахване на дублирането от index.php, тоест когато имаме такива URL адрес: "http://mysite.ru/index.php" И " http://mysite.ru/" води до една страница и URL адресиразлични, следователно дублиране, което ще се отрази зле на оптимизацията за търсачките. И с помощта REQUEST_URIможем да определим: с index.phpили не скриптът е бил извикан. И можем да направим пренасочване с index.php(ако е присъствал в REQUEST_URI) на без index.php. В резултат на това, когато изпращате такава заявка: " http://mysite.ru/index.php?id=5“, ще имаме пренасочване към URL адрес: "http://mysite.ru/?id=5". Тоест ние се отървахме от дублирането, като премахнахме от URL адрестова index.php.
- SCRIPT_NAME- относителен път към извикания скрипт.
Може би това са всички елементи глобален масив $_SERVER в PHPкоито се използват редовно. Трябва да ги познавате и да можете да ги използвате, когато е необходимо.
Във втория урок ще напишем още два класа и ще завършим напълно вътрешната част на скрипта.
Планирайте
Целта на тази поредица от уроци е да създаде просто приложение, което позволява на потребителите да се регистрират, влизат, излизат и променят настройките. Класът, който ще съдържа цялата информация за потребителя, ще се нарича User и ще бъде дефиниран във файла User.class.php. Класът, който ще отговаря за входа/изхода, ще се нарича UserTools (UserTools.class.php).
Малко за именуването на класове
Правилният етикет е файловете, които описват клас, да се именуват със същото име като самия клас. Това улеснява определянето на предназначението на всеки файл в папката с класове.
Също така е обичайно да се добавят .class или .inc в края на името на файла на класа. По този начин ние ясно дефинираме предназначението на файла и можем да използваме .htaccess, за да ограничим достъпа до тези файлове.
Потребителски клас (User.class.php)
Този клас ще дефинира всеки потребител. Тъй като това приложение расте, дефиницията на „Потребител“ може да се промени значително. За щастие, ООП програмирането улеснява добавянето на допълнителни потребителски атрибути.
Конструктор
В този клас ще използваме конструктор – това е функция, която се извиква автоматично при създаване на следващото копие на класа. Това ни позволява автоматично да публикуваме някои атрибути след създаването на проекта. В този клас конструкторът ще приеме един аргумент: асоциативен масив, който съдържа един ред от таблицата потребители на нашата база данни.
require_once "DB.class.php"; клас Потребител ( public $id; public $username; public $hashedPassword; public $email;
публичен $joinDate;
//Конструкторът се извиква, когато се създава нов обект//Взема асоциативен масив с реда на DB като аргумент. функция __construct($data) ( $this->id = (isset($data["id"])) ? $data["id"] : ""; $this->username = (isset($data[" потребителско име"])) ? $data["потребителско име"] : ""; $this->hashedPassword = (isset($data["password"])) ? $data["password"] : ""; $this- >email = (isset($data["email"])) ? $data["email"] : ""; $this->joinDate = (isset($data["join_date"])) $data[" join_date "] : ""; )
публична функция save($isNewUser = false) ( //създайте нов обект на база данни. $db = new DB(); //ако потребителят вече е регистриран и ние //просто актуализираме неговата информация. if(!$isNewUser ) ( //задаване на масива от данни $data = array("username" => ""$this->username"", "password" => ""$this->hashedPassword"",
"имейл" => ""$този->имейл"");
//актуализиране на реда в базата данни $db->update($data, "users", "id = ".$this->id); )else ( //ако потребителят се регистрира за първи път. $data = array("username" => ""$this->username"", "password" => ""$this->hashedPassword"" , "email" => "$this->email"", "join_date" => """.date("Y-m-d H:i:s",time())."""); id = $db ->insert($data, "users"); $this->joinDate = time(); ) ) ?>
Обяснение
Първата част от кода, извън зоната на класа, гарантира, че класът е свързан към базата данни (тъй като потребителският клас има функция, която изисква този клас).
Вместо променливи от класа „protected“ (използвани в 1-ви урок), ние ги определяме като „public“. Това означава, че всеки код извън класа има достъп до тези променливи, когато работи с обекта User.
Конструкторът взема масив, в който колоните в таблицата са ключове. Ние дефинираме променлива на клас, използвайки $this->variablename. В примера на този клас първо проверяваме дали стойността на даден ключ съществува. Ако да, тогава задаваме променливата на класа на тази стойност. В противен случай празният низ. Кодът използва кратката форма на нотация, ако:
$стойност = (3 == 4)? "А" : "Б";
В този пример проверяваме дали 3 е равно на четири! Ако да - тогава $value = “A”, не - $value = “B”. В нашия пример резултатът е $value = “B”.
Ние съхраняваме информация за Потребителите в базата данни
Функцията за запазване се използва за извършване на промени в таблицата на базата данни с текущите стойности в потребителския обект. Тази функция използва DB класа, който създадохме в първия урок. С помощта на променливи на класа се задава масивът $data. Ако потребителските данни се записват за първи път, тогава $isNewUser се предава като $true (false по подразбиране). Ако $isNewUser = $true, тогава се извиква функцията insert() на класа DB. В противен случай се извиква функцията update(). И в двата случая информацията от потребителския обект ще бъде запазена в базата данни.
Клас UserTools.class.php
Този клас ще съдържа функции, които са свързани с потребителите: login(), logout(), checkUsernameExists() и get(). Но с разширяването на това приложение можете да добавите много повече.
//UserTools.class.php require_once "User.class.php"; require_once "DB.class.php";
клас UserTools(
//Влезте на потребителя. Първо проверява дали //потребителското име и паролата съвпадат с ред в базата данни. //Ако е успешно, настройте променливите на сесията //и запазете потребителския обект в рамките.
вход в публична функция ($username, $password)
{
$hashedPassword = md5($парола); $result = mysql_query("SELECT * FROM users WHERE потребителско име = "$username" И парола = "$hashedPassword""); if(mysql_num_rows($result) == 1) ( $_SESSION["user"] = serialize(new User(mysql_fetch_assoc($result))); $_SESSION["login_time"] = time(); $_SESSION["logged_in "] = 1; връща истина; )else ( връща невярно; ) )
//Излизане на потребителя. Унищожете променливите на сесията. публична функция logout() ( unset($_SESSION["user"]); unset($_SESSION["login_time"]); unset($_SESSION["logged_in"]); session_destroy(); ) //Проверете дали съществува потребителско име. //Това се извиква по време на регистрация, за да се гарантира, че всички потребителски имена са уникални. публична функция checkUsernameExists($username) ( $result = mysql_query("изберете идентификатор от потребители, където потребителско име="$username""); if(mysql_num_rows($result) == 0) ( return false; )else( return true; )
}
//получаване на потребител //връща потребителски обект. Взема идентификатора на потребителя като входна публична функция get($id) ( $db = new DB(); $result = $db->select("users", "id = $id"); return new User($result );
?>
функция login().
Функцията login() е ясна от името си. Той взема потребителските аргументи $username и $password и проверява дали съвпадат. Ако всичко съвпада, създава потребителски обект с цялата информация и го записва в сесията. Моля, обърнете внимание, че използваме само функцията PHP serialize(). Той създава съхранена версия на обекта, която може лесно да бъде десериализирана с помощта на unserialize(). Освен това времето за влизане ще бъде запазено. Това може да се използва по-късно, за да предостави на потребителите информация за продължителността на престоя на сайта.
Може също да забележите, че задаваме $_SESSION["logged_in"] на 1. Това ни позволява лесно да проверяваме на всяка страница дали потребителят е влязъл. Достатъчно е да проверите само тази променлива.
функцията logout().
Също така проста функция. Функцията PHP unset() изчиства променливите в паметта, докато session_destroy() ще изтрие сесията.
функция checkUsernameExists().
Всеки, който знае английски, лесно ще разбере функцията. Той просто пита базата данни дали е използвано подобно влизане или не.
get() функция
Тази функция взема уникалния идентификатор на потребителя и прави заявка към базата данни, използвайки класа DB, а именно функцията select(). Той ще вземе асоциативен масив с определен брой потребителска информация и ще създаде нов потребителски обект, предавайки масива на конструктора.
Къде мога да използвам това? Например, ако създадете страница, която трябва да показва конкретни потребителски профили, ще трябва динамично да извличате тази информация. Ето как можете да го направите: (да приемем, че URL адресът е http://www.website.com/profile.php?userID=3)
//забележка: първо ще трябва да отворите връзка с база данни. //вижте част 1 за допълнителна информация как да направите това. //Ще трябва също така да се уверите, че сте включили файловете на класа.
$tools = нови потребителски инструменти(); $user = $tools->get($_REQUEST["userID"]); echo "Потребителско име: ".$user->username.""; echo "Присъединил се на: ".$user->joinDate."";
Лесно! Вярно ли е?
Последният щрих от страната на сървъра: global.inc.php
global.inc.php се изисква за всяка страница на сайта. Защо? По този начин ще поставим всички обичайни операции, които ще ни трябват на страницата. Например ще стартираме session_start(). Връзката с базата данни също ще се отвори.
require_once "classes/UserTools.class.php";
require_once "classes/DB.class.php";
//свързване към базата данни $db = new DB(); $db->свързване();
//инициализиране на обекта на UserTools $userTools = new UserTools(); //започнете сесията
session_start();
//опресняване на променливите на сесията, ако сте влезли if(isset($_SESSION["logged_in"])) ( $user = unserialize($_SESSION["user"]); $_SESSION["user"] = serialize($userTools-> get($user->id) ) ?>
Какво прави той?
Тук се случват няколко неща. Първо отваряме връзка към базата данни.
След свързване стартираме функцията session_start(). Функцията създава сесия или продължава текущата, ако потребителят вече е влязъл. Тъй като нашето приложение е създадено за потребители да влизат/излизат, тази функция е необходима на всяка страница.
След това проверяваме дали потребителят е влязъл. Ако е така, ще актуализираме $_SESSION["user"], за да отразим най-новата потребителска информация. Например, ако потребител промени своя имейл, старият ще бъде съхранен в сесията. Но с автоматична актуализация това няма да се случи.
С това приключваме втората част! Очаквайте последния урок по тази тема утре.
Всичко най-хубаво!
Съдържание
$user_info
Това са всички ключове, дефинирани за $user_info в loadUserSettings(). Някои със сигурност се разбират от само себе си.
групи
масив. Всички възможни групи членове са прикачени към потребител. Ключовете нямат значение. Стойностите са групите, дезинфекцирани като int, за всеки случай. Това включва:
- Първична група
- Група за преброяване на публикации
- Допълнителни групи. Те се съхраняват в базата данни като низ, разделен със запетая.
евентуално_робот
bool. Вярно е, ако агентът съответства на известен паяк, ако функцията е активирана, и ако е деактивирана, прави обосновано предположение.
документ за самоличност
int Съответства на стойността на базата данни на члена "id_member".!}
потребителско име
име
низ. Показаното им име.
електронна поща
passwd
език
е_гост
is_admin
тема
последно влизане
вътр. Времево клеймо на Unix.
ip
$_SERVER["REMOTE_ADDR"]
ip2
$_SERVER["BAN_CHECK_IP"]
публикации
вътр. Брой публикации.
времеви формат
низ. Персонализиран формат за strtftime().
време_отместване
вътр. Почасово отместване на потребителя спрямо времето във форума.
аватар
- url:низ
- име на файл: низ
- custom_dir:bool
- id_attach: вътр
smiley_set
съобщения
вътр. Брой PM, които имат.
непрочетени_съобщения
вътр. Брой непрочетени ЛС, които имат.
total_time_logged_in
приятели
низ. Списъкът на техните приятели, разделен със запетаи.
табла за игнориране
низ. Списъкът с табла, които те са игнорирали, разделен със запетаи.
игнориращи потребители
низ. Списъкът с потребители, които са избрали да игнорират, разделен със запетаи.
- В SMF 1.1.x само PM се игнорират.
- В SMF 2.0.x и по-нови тази функция е подобрена, за да скрие публикациите на игнорирания потребител.
внимание
вътр. Техните предупредителни точки.
разрешения
query_see_board
Списъкът на всички платки, които могат да видят като част от подготвен SQL оператор.
query_wanna_see_board
Списъкът с табла, които ИСКАТ да видят като част от подготвен SQL оператор.
mod_cache
is_mod
Булева стойност. Е невярно, освен в табла, където членът е модератор. Винаги е зададено.
5 февруари , 2017
Не знам никаква PHP рамка. Това е тъжно и срамно, но все още не е забранено от закона. Но в същото време искам да играя с REST API. Проблемът е, че php по подразбиране поддържа само $_GET и $_POST. А за RESTful услуга също трябва да можете да работите с PUT, DELETE и PATCH. И не е много очевидно как културно да се обработват много заявки като ВЗЕМЕТЕ http://site.ru/users, ИЗТРИЙТЕ http://site.ru/goods/5и други безобразия. Как да обвиете всички такива заявки в една точка, универсално да ги анализирате на части и да стартирате необходимия код за обработка на данните?
Почти всяка PHP рамка може да направи това веднага. Например Laravel, където маршрутизирането е реализирано ясно и просто. Но какво ще стане, ако не е необходимо да изучаваме нова голяма тема точно сега, а просто искаме бързо да стартираме проект с поддръжка на REST API? Това ще бъде обсъдено в статията.
Какво трябва да може да прави нашата RESTful услуга?
1. Поддържа всички 5 основни типа заявки: GET, POST, PUT, PATCH, DELETE.
2. Решете различни маршрути на изгледа
ПОСТ /стоки
PUT /стоки/(goodId)
GET /users/(userId)/info
и други произволно дълги вериги.
Внимание: тази статия не е за основите на REST API
Предполагам, че вече сте запознати с подхода REST и разбирате как работи. Ако не, тогава има много страхотни статии в интернет за основите на REST - не искам да ги дублирам, идеята ми е да покажа как се работи с REST на практика.
Каква функционалност ще поддържаме?
Нека разгледаме 2 субекта - продукти и потребители.
За продуктите опциите са както следва:
- 1. GET /стоки/(goodId)— Получаване на информация за продукта
- 2. ПОСТ /стоки— Добавяне на нов продукт
- 3. PUT /стоки/(goodId)— Редактиране на продукт
- 4. КРЕПКА /стоки/(goodId)— Редактиране на някои параметри на продукта
- 5. ИЗТРИВАНЕ /стоки/(goodId)— Премахване на продукт
За потребителите, за разнообразие, нека разгледаме няколко опции с GET
- 1. GET /потребители/(потребителско име)— Пълна информация за потребителя
- 2. GET /users/(userId)/info— Само обща информация за потребителя
- 3. GET /потребители/(userId)/поръчки— Списък с потребителски поръчки
Как ще работи това с родния PHP?
Първото нещо, което ще направим, е да настроим .htaccess, така че всички заявки да се пренасочват към файла index.php. Именно той ще се занимава с извличане на данни.
Второ, нека решим от какви данни се нуждаем и да напишем кода, за да ги получим – в index.php.
Ние се интересуваме от 3 вида данни:
- 1. Метод на заявка (GET, POST, PUT, PATCH или DELETE)
- 2. Данни от URL, например, потребители/(userId)/информация - необходими са всичките 3 параметъра
- 3. Данни от тялото на заявката
.htaccess
Нека създадем .htaccess файл в корена на проекта
RewriteEngine On RewriteCond %(REQUEST_FILENAME) !-f RewriteRule ^(.+)$ index.php?q=$1
С тези мистериозни редове ви заповядваме да направите това:
1 - изпращайте всички заявки от всякакъв вид до king-файла index.php
2 - направете низа в URL адреса достъпен в index.php в параметъра get q. Тоест данни от URL като /потребители/(userId)/информацияще получим от $_GET["q"].
index.php
Нека разгледаме index.php ред по ред. Първо, нека вземем метода на заявката.
// Дефиниране на метода на заявката $method = $_SERVER["REQUEST_METHOD"];
След това данните от тялото на заявката
// Получаване на данни от тялото на заявката $formData = getFormData($method);
За GET и POST е лесно да изтеглите данни от съответните масиви $_GET и $_POST. Но за други методи трябва да сте малко перверзни. Кодът за тях се изтегля от потока php://вход, кодът е лесен за Google, току-що написах обща обвивка - функцията getFormData($method)
// Получаване на данни от функцията на тялото на заявката getFormData($method) ( // GET или POST: връщане на данни, каквито са if ($method === "GET") return $_GET; if ($method === "POST" ) return $_POST; // PUT, PATCH или DELETE $data(); explode("&", file_get_contents("php://input")); foreach($exploded as $pair) ($item = explode ("=", $pair); if (count($item) == 2) ( $data = urldecode($item); ) ) върне $data;
Тоест получихме необходимите данни, като скрихме всички подробности в getFormData - добре, страхотно. Да преминем към най-интересната част – маршрутизирането.
// Анализирайте URL адреса $url = (isset($_GET["q"]))? $_GET["q"] : ""; $url = rtrim($url, "/"); $urls = експлодиране("/", $url);
По-горе научихме, че .htaccess ще постави параметри от URL адреса в q-параметъра на масива $_GET. Тоест $_GET["q"] ще съдържа нещо подобно: потребители/10. Независимо кой метод използваме за изпълнение на заявката.
А експлозия("/", $url)преобразува този низ в масив за нас, с който вече можем да работим. Така направете толкова дълги вериги от заявки, колкото желаете, например
ВЗЕМЕТЕ /goods/page/2/limit/10/sort/price_asc
И бъдете сигурни, че ще получите масив
$urls = array("стоки", "страница", "2", "ограничение", "10", "сортирай", "price_asc");
Сега имаме всички данни, трябва да направим нещо полезно с тях. И само 4 реда код ще го направят
// Дефиниране на рутера и url данните $router = $urls; $urlData = array_slice($urls, 1); // Свържете файла на рутера и стартирайте главната функция include_once "routers/". $ рутер. ".php"; route($method, $urlData, $formData);
Схващаш ли? Създаваме папка рутери, в която поставяме файлове, които манипулират един обект: продукти или потребители. В същото време се съгласяваме, че имената на файловете съвпадат с първия параметър в urlData - това ще бъде рутерът, $router. И този рутер трябва да бъде премахнат от urlData; вече не се нуждаем от него и се използва само за свързване на необходимия файл. array_slice($urls, 1)и ще ни даде всички елементи на масива с изключение на първия.
Сега всичко, което остава, е да свържете желания файл на рутера и да стартирате функцията за маршрут с три параметъра. Какъв е този функционален маршрут? Нека се съгласим, че във всеки файл на рутера ще бъде дефинирана функция, която въз основа на входните параметри ще определи какво действие е инициирал потребителят и ще изпълни необходимия код. Сега това ще стане по-ясно. Нека разгледаме първата заявка - получаване на данни за продукт.
GET /стоки/(goodId)
Файл routers/goods.php
// Функция на рутера route($method, $urlData, $formData) ( // Получаване на информация за продукт // GET /goods/(goodId) if ($method === "GET" && count($urlData) == = 1) ( // Вземете идентификатора на продукта $goodId = $urlData; // Изтеглете продукта от базата данни... // Изведете отговора на клиента echo json_encode(array("method" => "GET", "id" => $goodId, "good" => "phone", "price" => 10000)); грешка" => "Грешна заявка"));
Съдържанието на файла е една голяма маршрутна функция, която в зависимост от подадените параметри извършва необходимите действия. Ако методът GET и 1 параметър (goodId) се предават на urlData, тогава това е заявка за получаване на данни за продукт.
Внимание: примерът е много опростен
В реалния живот, разбира се, трябва допълнително да проверите входните параметри, например дали goodId е число. Вместо да пишете кода тук, вероятно ще включите необходимия клас. И за да получите продукта, създайте обект от този клас и извикайте някакъв метод върху него.
Или може би прехвърлете управлението на някакъв контролер, който вече ще се погрижи за инициализиране на необходимите модели. Има много опции, ние разглеждаме само общата структура на кода.
В отговора на клиента показваме необходимите данни: името на продукта и неговата цена. ID на продукта и методът са напълно незадължителни в реално приложение. Показваме ги само за да сме сигурни, че правилният метод е извикан с правилните параметри.
Нека опитаме с пример: отворете конзолата на браузъра си и стартирайте кода
$.ajax((url: "/examples/rest/goods/10", метод: "GET", dataType: "json", успех: функция (отговор)(console.log("отговор:", отговор))) )
Кодът ще изпрати заявка до сървъра, където съм разположил подобно приложение и ще изведе отговор. Уверете се, че маршрутът, който ви интересува, е /стока/10наистина работи. В раздела Мрежа ще забележите същата заявка.
И да, /examples/rest е основният път на нашето тестово приложение към сайта
Ако сте по-свикнали да използвате curl в конзолата, тогава стартирайте това в терминала - отговорът ще бъде същият и дори със заглавки от сървъра.
Curl -X GET https://site/examples/rest/goods/10 -i 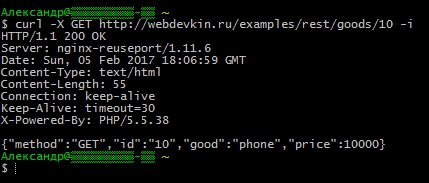
В края на функцията написахме следния код.
// Връща заглавка за грешка ("HTTP/1.0 400 Bad Request"); echo json_encode(array("error" => "Bad Request"));
Това означава, че ако сме направили грешка с параметрите или исканият маршрут не е дефиниран, ще върнем грешката 400 Bad Request на клиента. Например, добавете нещо като това към URL адреса: стоки/10/друг_параметри ще видите грешка в конзолата и отговор 400 - кривата заявка не е преминала.
Чрез http кодове за отговор на сървъра
Няма да се занимаваме с извеждане на различни кодове, въпреки че това си струва да се направи според REST. Има много клиентски грешки. Дори в нашия прост случай, 405 е подходящо в случай на неправилно подаден метод. Не искам да усложнявам нещата нарочно.
Ако успее, нашият сървър винаги ще връща 200 OK. За щастие, когато създавате ресурс, трябва да дадете 201 Created. Но отново, от гледна точка на опростяване, ние ще отхвърлим тези тънкости, но в реален проект можете лесно да ги приложите сами.
Честно казано, статията е завършена. Мисля, че вече разбирате подхода, как се разрешават всички маршрути, извличат данни, как да ги тествате, как да добавяте нови заявки и т.н. Но за да завърша изображението, ще дам изпълнението на останалите 7 заявки, които очертахме в началото на статията. По пътя ще направя няколко интересни коментара и накрая ще публикувам архив с изходния код.
ПОСТ /стоки
Добавяне на нов продукт
// Добавяне на нов продукт // POST /goods if ($method === "POST" && празен($urlData)) ( // Добавяне на продукт към базата данни... // Изведе отговора на клиента echo json_encode (масив("method" => "POST", "id" => rand(1, 100), "formData" => $formData));
urlData вече е празен, но се използва formData - просто ще го покажем на клиента.
Как да го направя "правилно"?
Съгласно каноните на REST, в заявка за публикация трябва да върнете само идентификатора на създадения обект или url, от който този обект може да бъде получен. Тоест, отговорът ще бъде или просто число - (goodId), или /стоки/(goodId).
Защо написах "правилно" в кавички? Да, защото REST не е набор от строги правила, а препоръки. А как ще го реализирате зависи от вашите предпочитания или вече приети договорености по конкретен проект.
Само имайте предвид, че друг програмист, който чете кода и е запознат с подхода REST, ще очаква в отговора на заявка за публикация идентификатора на създадения обект или url, от който данните за този обект могат да бъдат извлечени с искане за получаване.
Тестване от конзолата
$.ajax((url: "/examples/rest/goods/", метод: "POST", данни: (good: "notebook", цена: 20000), dataType: "json", успех: функция (отговор)( console.log("отговор:", отговор))))
Curl -X POST https://site/examples/rest/goods/ --data "good=notebook&price=20000" -i
PUT /стоки/(goodId)
Редактиране на продукт
// Актуализирайте всички данни за продукта // PUT /goods/(goodId) if ($method === "PUT" && count($urlData) === 1) ( // Вземете идентификатора на продукта $goodId = $urlData; / / Актуализирайте всички продуктови полета в базата данни... // Изведете отговора на клиента echo json_encode(array("method" => "PUT", "id" => $goodId, "formData" => $formData)) ;
Тук всички данни вече се използват максимално. ID на продукта се извлича от urlData, а свойствата се извличат от formData.
Тестване от конзолата
$.ajax((url: "/examples/rest/goods/15", метод: "PUT", данни: (good: "notebook", цена: 20000), dataType: "json", успех: функция (отговор) (console.log("отговор:", отговор))))
Curl -X PUT https://site/examples/rest/goods/15 --data "good=notebook&price=20000" -i
КРЕПКА /стоки/(goodId)
Частична актуализация на продукта
// Частична актуализация на данните за продукта // PATCH /goods/(goodId) if ($method === "PATCH" && count($urlData) === 1) ( // Вземете идентификатора на продукта $goodId = $urlData; // Ние актуализираме само посочените продуктови полета в базата данни... // Извеждаме отговора на клиента echo json_encode(array("method" => "PATCH", "id" => $goodId, "formData" => $formData));
Тестване от конзолата
$.ajax((url: "/examples/rest/goods/15", метод: "PATCH", данни: (цена: 25000), dataType: "json", успех: функция (отговор)(console.log(" отговор:", отговор))))
Curl -X ПАТЧ https://site/examples/rest/goods/15 --data "price=25000" -i
Защо цялото това парадиране с PUT и PATCH?
Не е ли достатъчен един PUT? Те не извършват ли същото действие - обновяване на данните на обекта?
Точно така - външно действието е едно. Разликата е в предаваните данни.
PUT предполага това всичкообектни полета, а PATCH - само променен. Изпратените в тялото на заявката. Моля, обърнете внимание, че в предишния PUT предадохме както името на продукта, така и цената. А в PATCH - само цената. Тоест изпратихме само променени данни на сървъра.
Дали имате нужда от PATCH - решете сами. Но не забравяйте онзи програмист за четене на код, който споменах по-горе.
ИЗТРИВАНЕ /стоки/(goodId)
Премахване на продукт
// Изтриване на продукт // DELETE /goods/(goodId) if ($method === "DELETE" && count($urlData) === 1) ( // Вземете идентификатора на продукта $goodId = $urlData; // Изтриване на продукта от базата данни... // Извеждане на отговора на клиента echo json_encode(array("method" => "DELETE", "id" => $goodId));
Тестване от конзолата
$.ajax((url: "/examples/rest/goods/20", метод: "DELETE", dataType: "json", успех: функция (отговор)(console.log("отговор:", отговор))) )
Curl -X ИЗТРИВАНЕ https://site/examples/rest/goods/20 -i
Всичко е ясно с искането DELETE. Сега нека да разгледаме работата с потребителите - потребителския рутер и съответно файла users.php
GET /потребители/(потребителско име)
Извличане на всички потребителски данни. Ако GET заявката е като /потребители/(потребителски идентификатор), тогава ще върнем цялата информация за потребителя, ако е посочена допълнително /информацияили /поръчки, след това, съответно, само обща информация или списък с поръчки.
// Функция на рутера route($method, $urlData, $formData) ( // Получаване на цялата информация за потребителя // GET /users/(userId) if ($method === "GET" && count($urlData) = = = 1) ( // Получаване на идентификатора на продукта $userId = $urlData; // Извличане на всички данни за потребителя от базата данни... // Извеждане на отговора на клиента echo json_encode(array("method" => " GET", "id" = > $userId, "info" => array("email" => " [имейл защитен]", "name" => "Webdevkin"), "orders" => array(array("orderId" => 5, "summa" => 2000, "orderDate" => "01/12/2017"), array (" orderId" => 8, "summa" => 5000, "orderDate" => "02/03/2017"))) // Връщане на заглавката на грешката ("HTTP/1.0 400 Bad Request" echo json_encode( array("error" => "Bad Request"));
Тестване от конзолата
$.ajax((url: "/examples/rest/users/5", метод: "GET", dataType: "json", успех: функция (отговор)(console.log("отговор:", отговор))) )
Curl -X GET https://site/examples/rest/users/5 -i
GET /users/(userId)/info
Обща информация за потребителя
// Получаване на обща информация за потребителя // GET /users/(userId)/info if ($method === "GET" && count($urlData) === 2 && $urlData === "info") ( / / Получаване на идентификатора на продукта $userId = $urlData; // Извличане на общи данни за потребителя от базата данни... // Извеждане на отговора на клиента echo json_encode(array("method" => "GET", "id " => $userId, " info" => array("email" => " [имейл защитен]", "име" => "Webdevkin"))); връщане; )
Тестване от конзолата
$.ajax((url: "/examples/rest/users/5/info", метод: "GET", dataType: "json", успех: функция (отговор)(console.log("отговор:", отговор) )))
Curl -X GET https://site/examples/rest/users/5/info -i
GET /потребители/(userId)/поръчки
Получаване на списък с потребителски поръчки
// Получаване на потребителски поръчки // GET /users/(userId)/orders if ($method === "GET" && count($urlData) === 2 && $urlData === "orders") ( // Get идентификатор на продукта $userId = $urlData; // Извличане на данни за поръчките на потребителя от базата данни... // Извеждане на отговора на клиента echo json_encode(array("method" => "GET", "id" => $ userId, "orders" => array(array("orderId" => 5, "summa" => 2000, "orderDate" => "01/12/2017"), array("orderId" => 8, "summa " => 5000, "orderDate " => "02/03/2017")))); връщане; )
Тестване от конзолата
$.ajax((url: "/examples/rest/users/5/orders", метод: "GET", dataType: "json", успех: функция (отговор)(console.log("отговор:", отговор) )))
Curl -X GET https://site/examples/rest/users/5/orders -i
Резултати и източници
Източници от примери за статии -
Както можете да видите, организирането на поддръжка на REST API в родния php се оказа не толкова трудно и по напълно законни начини. Основното нещо е поддръжката на маршрути и нестандартни PHP методи PUT, PATCH и DELETE.
Основният код, който прилага тази поддръжка, се вписва в 3 дузини реда на index.php. Останалото е просто сбруя, която може да се приложи по какъвто начин желаете. Предложих да направите това под формата на плъгин рутер файлове, чиито имена съответстват на обектите на вашия проект. Но можете да използвате въображението си и да намерите по-интересно решение.





